딥러닝 모델 서비스 A-Z 1편 - 연산 최적화 및 모델 경량화
딥러닝 모델 서비스 A-Z 1편



대화를 더 잘하기 위해 딥러닝 모델들은 점점 더 크고 무거워지고 있습니다. 그에 비례해서 빠르고 효율적으로 서비스하기 위한 난이도 또한 나날이 높아지고 있습니다.
이번 글에서는 핑퐁팀이 딥러닝 모델을 서비스하기 위해 고려한 것들을 소개해드리고자 합니다.
목차
딥러닝 모델 서비스의 차이점
딥러닝 모델을 서비스하는 일은 대부분의 서비스들과 달리 몇 가지 큰 차이점이 있습니다. 그 중에서도 가장 중요한 차이점은, 딥러닝 모델 서비스는 매우 많은 연산(Model Inference)을 처리해야한다는 점입니다.
Transformer 모델의 출현 이후 SOTA 모델들의 Parameter 수는 기하급수적으로 증가하고 있는데, 반면 우리에게 주어진 Computing Power 는 선형적으로 증가하고 있습니다. (그것도 매우 낮은 계수로…)

효율적인 서비스를 위해, (== 기하급수적인 통장 지출을 막기 위해) 아래 두 가지 요소를 적용해야 합니다.
이를 알아보기 전에, 연산을 처리하는 환경을 짚고 넘어가야합니다.
연산을 수행하는 환경은 두 가지인데요, CPU만 사용하거나, GPU를 함께 사용하는 것입니다.
“딥러닝? 그거 무조건 GPU 짱짱 아니야?” 라고 생각하실 수 있지만, 학습이 아니라 운영 시에는 꼭 그렇지만은 않습니다. 각각의 환경은 아래와 같은 특징이 있습니다.
- CPU
- 상대적으로 비용이 저렴하다
- Scale Up/Out 이 쉽다
- 배포 구성시에 제약이 (거의) 없다
- (단일 Inference 를 기준으로) 느리다
- GPU
- 상대적으로 비싸다
- Scale Up/Out 이 어렵다
- 배포 구성시에 제약이 많다
- (단일 Inference 를 기준으로) 빠르다
(핑퐁팀이 현재 사용 중인 AWS 를 기준으로 비교했습니다.)
먼저 가격을 살펴보면, GPU 인스턴스의 경우 가장 작은 사양의 g4dn.xlarge(4vCPU, 16GiB, 1GPU)도 시간당 $0.647부터 시작합니다.
반면 CPU 인스턴스의 경우 비슷한 사양의 t3a.xlarge(4vCPU, 16GiB)가 시간당 $0.1872입니다.
다음으로 Scalability 에 대해 살펴보겠습니다. CPU 인스턴스의 경우 다양한 조합의 vCPU, Memory 를 가진 인스턴스 타입들이 존재하므로 요구하는 사양에 맞춰 Scale Up/Out 을 하기가 쉽습니다. 반면 GPU 인스턴스의 경우 조합이 한정적이고, 하나의 인스턴스가 매우 비싸서 작은 인스턴스를 여러 대 띄우는 식의 구성을 하기가 어렵습니다.
예시1) 높은 CPU 사용량을 (혹은 RAM) 요구하는 반면 상대적으로 낮은 GPU 사용량을 요구하는 서비스의 경우, 더 큰 vCPU 및 Memory 를 가지는 인스턴스로 Scale Up을 할 때 상대적으로 더 많은 돈을 지불해야한다.
예시2) 낮은 CPU 사용량을 (혹은 RAM) 요구하는 반면 상대적으로 높은 GPU 사용량을 요구하는 서비스의 경우, 같은 CPU 및 Memory 사양에 GPU 의 개수만 많은 인스턴스 타입이 존재하지 않으므로 (CPU, Memory 사용량이 적음에도) 동일한 인스턴스를 추가해야한다.
또한, 배포 구성시 제약사항에도 차이가 있습니다.
GPU를 사용하는 경우, Cloud 서비스 중 지원하지 않거나 업데이트가 느리게 되어 현재 사용할 수 없는 경우가 많습니다. 예를 들어, AWS의 ECS Fargate의 경우 현재(2020.03.13 기준) GPU 지원이 되지 않습니다. 그 외에도, GPU 인스턴스를 지원하지 않는 경우가 많습니다.
지금까지 말씀드린 내용을 읽고나신 후에, “아니 그러면 도대체 GPU로 서비스는 왜 하는거야?”라고 생각하실 수 있습니다. GPU 인스턴스는 (단일 Inference 를 기준으로) 연산 속도가 매우 빠릅니다. 응답 시간이 중요한 서비스는 GPU를 사용하면 CPU만 사용하는 환경에 비해 매우 큰 속도 향상을 기대할 수 있습니다.
연산 최적화
Library Support
Model Inference에는 많은 행렬 연산이 필요한데요, 행렬 연산에 최적화된 Library (또는 Instruction Extension)들이 있습니다.
각 요소에 대한 자세한 설명은 글의 범위를 넘어서므로 CPU에서 사용 가능한 MKL-DNN과 GPU에서 사용 가능한 TensorRT를 위주로 간단히 살펴보겠습니다.
MKL-DNN
MKL-DNN은 Intel에서 만든 딥러닝 라이브러리입니다.(Math Kernel Library for Deep Neural Networks)
TensorFlow는 MKL-DNN 으로 빌드된 패키지를 Anaconda에서 받을 수 있습니다.
PyTorch는 MKL-DNN 빌드 여부를 확인한 후에 사용하도록 설정할 수 있습니다.
사용하는 환경에 따라 차이가 있을 수 있으나 Intel의 자료를 참고하여 살펴보면, PyTorch에서 MKL-DNN 지원 유무에 따라 매우 큰 차이를 보인다는 것을 확인하실 수 있습니다.


TensorRT
TensorRT는 NVIDIA에서 만든 딥러닝 추론용 SDK입니다. TensorRT를 활용하여 여러 Layer를 거치는 구조를 하나의 Layer로 합쳐서 최적화할 수 있습니다.
아래 왼쪽의 그림과 같은 CNN 구조에서 Convolution, Bias and ReLU Layer를 하나로 합쳐서 CBR Layer로 만들고, 다시 이를 통합해서 연산을 더 효율적으로 처리하는 구조로 바꿀 수 있습니다.
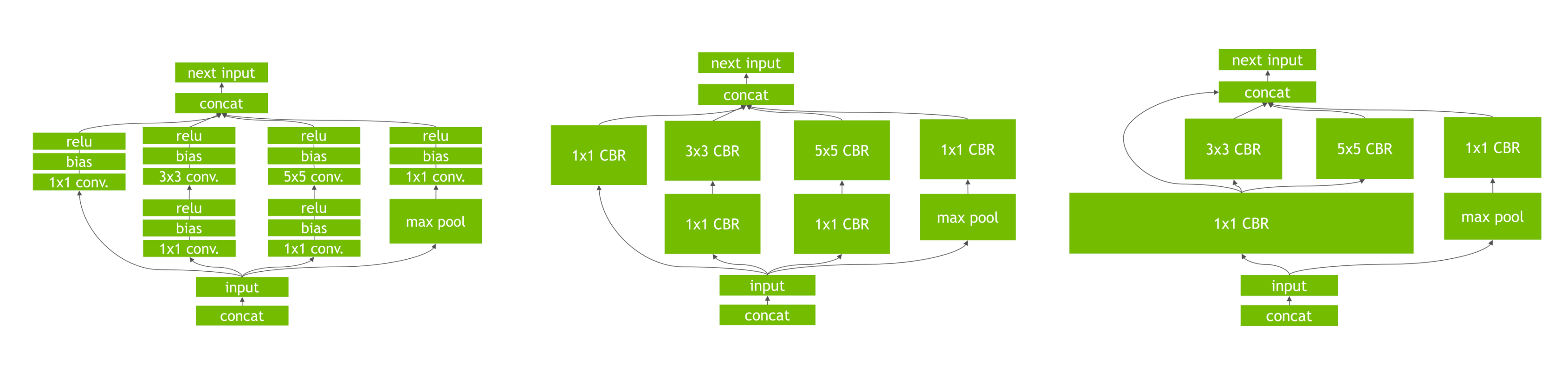
그 외에도, 관련 키워드를 추가적으로 찾아보시고 참고하시면 도움이 될 것입니다.
Python Bottleneck
일반적으로 사용하는 CPython은 GIL으로 인해 Multi-threading 성능에 제약이 생깁니다. 또한, Python의 GC 때문에 Response Time이 크게 튀는 경우가 존재합니다. Production 환경에서 Flask 등과 같은 Python 웹서버를 통해 서비스한다면, Request Throughput 및 GC 로 인해 가끔 지나치게 느린 것이 문제가 될 수 있습니다.
- TensorFlow는 TensorFlow Serving을 통해 Serving 할 수 있습니다.
- PyTorch는 TorchScript 및 libTorch 를 통해 모델을 Jit Compile 하고, C++ 환경에서 Serving 할 수 있습니다.
핑퐁팀은 딥러닝 모델 학습시에 PyTorch를 사용하고, 이를 TensorFlow(>= 2.0)로 변환하여 TensorFlow Serving을 통해 Serving하고 있습니다. TensorFlow 가 2.0으로 업데이트되면서 PyTorch와 거의 똑같은 코드로 모델을 변환할 수 있고, TensorFlow Serving이 gRPC 와 ProtoBuf 를 지원하여 PyTorch에 비해 서비스 환경을 최적화하는데 유리하기 때문입니다.
이 외에도 cuBERT등을 참조하시면 도움이 될 것입니다.
병렬처리를 위한 환경변수 설정
병렬처리를 위해 사용하는 양대산맥인 OpenMP와 TBB의 환경변수를 적절히 설정하는 것만으로도 큰 성능 향상을 기대할 수 있습니다.
핑퐁팀에서는 아래와 같은 변수 설정으로 10~15%의 성능 향상을 얻었습니다.
CORES=`lscpu | grep Core | awk '{print $4}'`
SOCKETS=`lscpu | grep Socket | awk '{print $2}'`
TOTAL_CORES=`expr $CORES \* $SOCKETS`
KMP_SETTING="KMP_AFFINITY=granularity=fine,compact,1,0"
KMP_BLOCKTIME=1
export OMP_NUM_THREADS=$TOTAL_CORES
export $KMP_SETTING
export KMP_BLOCKTIME=$KMP_BLOCKTIME
echo -e "### using OMP_NUM_THREADS=$TOTAL_CORES"
echo -e "### using $KMP_SETTING"
echo -e "### using KMP_BLOCKTIME=$KMP_BLOCKTIME\n"
# 서버 실행 커맨드
./run-server
모델과 환경에 따라 최적화된 옵션은 다를 수 있으므로, OpenMP* Implementation-Defined Behaviors 및 Linking with Threading Libraries 를 참고하셔서 실험을 통해 결정하시면 코드 변경 없이 만족할만한 성능 향상을 기대할 수 있을 것이라 생각합니다.
Cloud Support
딥러닝 모델 서비스들이 많아지면서 AWS와 같은 Cloud 업체에서 자체적으로 딥러닝 연산에 최적화된 운영 환경을 제공하고 있습니다. AWS re:Invent 2019에서 공개된 EC2 Inf1 인스턴스가 대표적인데요. AWS Inferentia라는 자체 칩을 사용해서 기존 GPU 기반 인스턴스에 비해 더 높은 성능 및 낮은 비용으로 연산을 처리할 수 있습니다.
EC2 Inf1 인스턴스를 AWS Neuron SDK를 지원하는 AMI로 시동하면 Inferentia 칩을 사용할 수 있도록 설계된 Tensorflow 혹은 PyTorch를 받을 수 있습니다. Neuron SDK를 통해 기존 모델을 새로 Compile한 후, 이를 로드해서 사용할 수 있습니다. Tutorial을 참고하시면 도움이 될 것입니다.
핑퐁팀에서 내부적으로 테스트한 결과 유의미한 성능 향상을 확인할 수 있었지만 아래와 같은 이유로 아직 도입하지 못했습니다.
- Inf1은 현재 한국 Region에서 사용할 수 없습니다.
- AWS Neuron SDK가 TensorFlow, PyTorch 최신 버전을 지원하지 않습니다.
사용하시는 모델에 대해 성능을 테스트해보시고 추후 도입을 검토해보시면 도움이 될 것입니다.
모델 경량화
연산 최적화와 달리, 모델 경량화는 학습 과정에서 이루어져야합니다. 모델 경량화에는 크게 세 가지 방법이 존재합니다. 각각 Pruning, Quantization, Distillation인데요. 세 가지 방식 모두 큰 모델을 작게 바꾸는 것은 같으나 접근 방식에 차이가 있습니다.
- 중요하지 않은 부분을 적절히 가지치기를 해서 줄일 것이냐 (Pruning)
- 해상도를 낮춰서 작게 만들 것이냐 (Quantization)
- 사이즈 자체를 작게 만들 것이냐 (Distillation)
아래 그림을 참고하시면 이해에 도움이 될 것입니다.

Pruning과 Quantization은 아래를 참고하시면 도움이 될 것 입니다.
- TensorFlow는 NVIDIA 에서 제공하는 SDK인 TensorRT를 이용하여 경량화할 수 있습니다.
- PyTorch는 NVIDIA 에서 제공하는 APEX를 이용하여 경량화할 수 있습니다.
단, APEX를 사용하시면 주의하실 것들이 있습니다.
- PyTorch 버전이 1.3.1 이어야 합니다. 1.3.0 버전은 버그가 있어서 FP16 연산이 지원되지 않습니다.
- PyTorch 바이너리를 빌드한 CUDA 버전과 로컬 머신의 CUDA 버전이 소숫점 한 개까지 일치해야합니다.
- PyTorch 1.3.1이 10.1 버전으로 빌드되었으므로, 반드시 CUDA 10.1 버전을 사용하여야 합니다.
- Pip 19.3.1 버전에 버그가 있으므로, Pip 19.0 버전으로 다운그레이드하여 설치해야합니다.
Distillation은 기존 모델로 경량화된 새로운 모델을 학습시켜야 합니다. 학습 방법 및 자세한 내용은 이 글의 범위를 넘어서므로 추후에 게시될 Distillation 관련 글을 참고해주세요!
마치며
딥러닝 모델이 높은 성능을 기록하는 것뿐만 아니라, 이를 통해 사용자에게 좋은 경험을 주는 서비스를 제공하는 것은 매우 중요한 일입니다. 이번 글에서는 핑퐁팀이 딥러닝 모델을 안정적으로 서비스하기 위해 고려하고 적용한 사항들에 대해서 알아보았습니다. 더 많은 사람들에게 핑퐁이 친근하고, 일상적인 대화를 할 수 있도록 더 열심히 노력하겠습니다. 다음 글에서 만나요~~ 😝
참고자료
- Compressing BERT for faster prediction
- Deploying Deep Neural Networks with NVIDIA TensorRT
- Intel and Facebook* collaborate to boost PyTorch* CPU performance
- TensorFlow Serving
- OpenMP* Implementation-Defined Behaviors
- Intel® C++ Compiler 19.1 Developer Guide and Reference
- AWS Neuron SDK Tutorial