ACL 2022 Review
핑퐁팀과 함께하는 ACL 2022 Review

올해로 60회를 맞은 Annual Meeting of the Association for Computational Linguistics (ACL)는 자연어 처리 분야 최고의 국제 컨퍼런스로서 최신 NLP 연구들이 발표되는 행사입니다. 엔데믹 상황으로 접어들면서 올해 ACL은 오프라인과 온라인에서 동시에 하이브리드 형태로 진행되었습니다.
저희 핑퐁팀의 이성현님, 장성보님은 이번 ACL 2022에 Accept된 Toward Interpretable Semantic Textual Similarity via Optimal Transport-based Contrastive Sentence Learning 논문 발표를 위해 행사 장소인 아일랜드로 떠나셨고, 나머지 팀원들은 일주일 동안 별도의 공간을 마련하여 온라인으로 논문 발표를 듣고 함께 토론하는 즐거운 시간을 가졌습니다!

발표된 논문 중 인상 깊었던 논문을 각자 한 편씩 선정하여 총 12편을 간단히 리뷰해보았습니다. 현재 핑퐁팀이 관심있게 보고있는 연구라고 할 수 있을 것 같아요! 재미있게 읽어주세요 😀
- PPT: Pre-trained Prompt Tuning for Few-shot Learning
- A Contrastive Framework for Learning Sentence Representations from Pairwise and Triple-wise Perspective in Angular Space
- Memorisation versus Generalisation in Pre-trained Language Models
- Multi-View Document Representation Learning for Open-Domain Dense Retrieval
- Contextual Representation Learning beyond Masked Language Modeling
- A Closer Look at How Fine-tuning Changes BERT
- Overcoming Catastrophic Forgetting beyond Continual Learning: Balanced Training for Neural Machine Translation
- A Taxonomy of Empathetic Questions in Social Dialogs
- Ditch the Gold Standard: Re-evaluating Conversational Question Answering
- VALSE: A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic Phenomena
- What is wrong with you?: Leveraging User Sentiment for Automatic Dialog Evaluation
- Debiased Contrastive Learning of Unsupervised Sentence Representations
PPT: Pre-trained Prompt Tuning for Few-shot Learning
작성자: 구상준
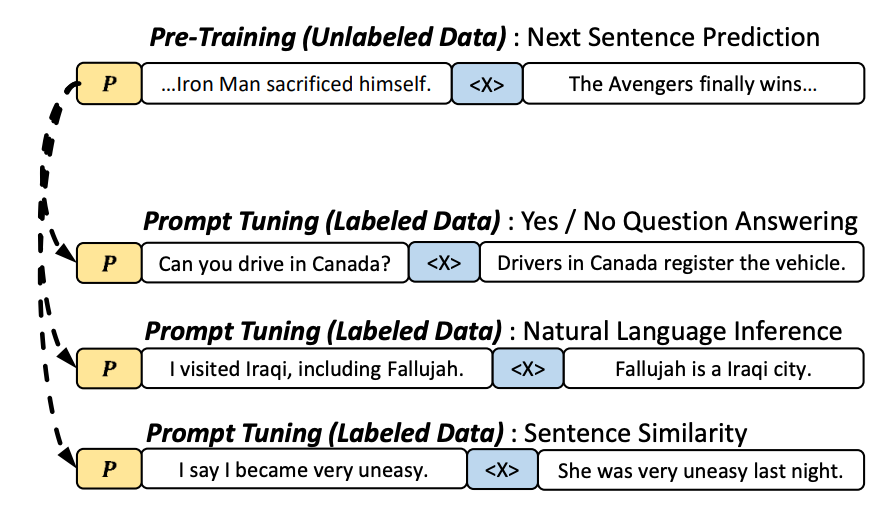
2022년 현재 NLP의 연구 트렌드는 대형 생성 모델이 Zero-shot, Few-shot 환경에서 문제를 풀 수 있도록 유도하는 Prompt를 활용하고 설계하는 것입니다. 하지만 이런 방식은 성능이 매우 불안정하다는 단점을 보입니다.
본 논문에서는 이러한 단점은 Pre-training 할 때 Prompt 튜닝에 대해서 고려되지 못했기 때문에 발생하는 것이라고 분석했습니다. 따라서 논문의 저자들은 Pre-training의 Next Sentence Prediction과 동일한 형태로 다음 문제들을 풀 수 있는 Prompt를 설계하였습니다.
- Sentence-Pair Classification Task: 두 입력 문장이 주어졌을 때, 예-아니오를 판단하는 Task
- Multiple-Choice Classification Task: 여러 문장 입력 보기 중에 하나를 선택하는 Task
- Single Sentence Classification Task: 한 문장에 대한 라벨을 선택하는 Task
제안한 방법으로 학습된 모델은 기존의 Prompt Fine-tuning 모델보다 더 높은 성능을 보였습니다.
A Contrastive Framework for Learning Sentence Representations from Pairwise and Triple-wise Perspective in Angular Space
작성자: 이녕우
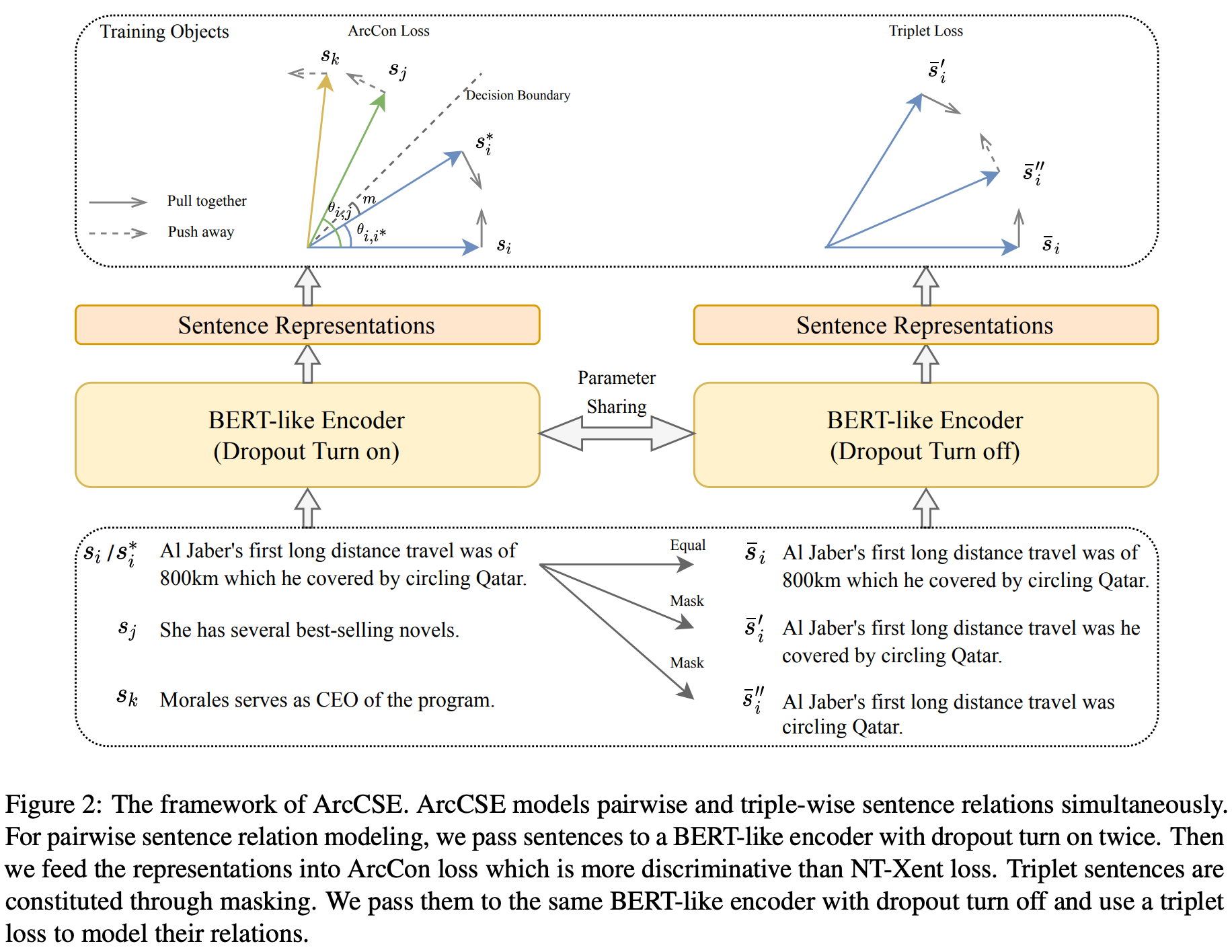
본 논문은 언어 모델의 Sentence Representation 품질이 좋지 못하다는 문제를 지적합니다. 최근 Contrastive Learning 기반의 방법론들이 유망한 결과를 보여주고 있으나 여전히 다음과 같은 한계들이 있습니다.
- 대부분이 Positive-Negative Pairs를 구성하여 학습을 진행하나, 이러한 구성만으로는 다양한 수준의 문장들 간 변별력을 학습하기에 충분하지 않습니다.
- 마찬가지로, NT-Xent Loss와 같은 Softmax-based Loss는 문장 간 변별력을 학습하는 데 부적합합니다.
이러한 한계를 해결하기 위해, 본 논문은 ArcCSE라는 Sentence Representation Learning에 적합한 Contrastive Learning Framework를 제안합니다. ArcCSE는 다음 2가지 Components로 구성됩니다:
- ArcCon Loss (Additive Angular Margin Contrastive Loss): Angular Space에서 Decision Margin을 최대화하여 두 문장 간의 변별력을 강화
- Modeling Entailment Relation of Triplet Sentences: 세 문장 간의 관계를 파악하도록 하여 문장들 간 Partial Order를 모델링
ArcCSE로 학습한 모델은 STS, SentEval과 같은 Tasks에서 기존 SOTA 방법들을 압도했으며, 실제 Sentence Representation을 시각화한 자료에서 다른 방법들보다 더 나은 변별력을 보였습니다.
Memorisation versus Generalisation in Pre-trained Language Models
작성자: 정다운
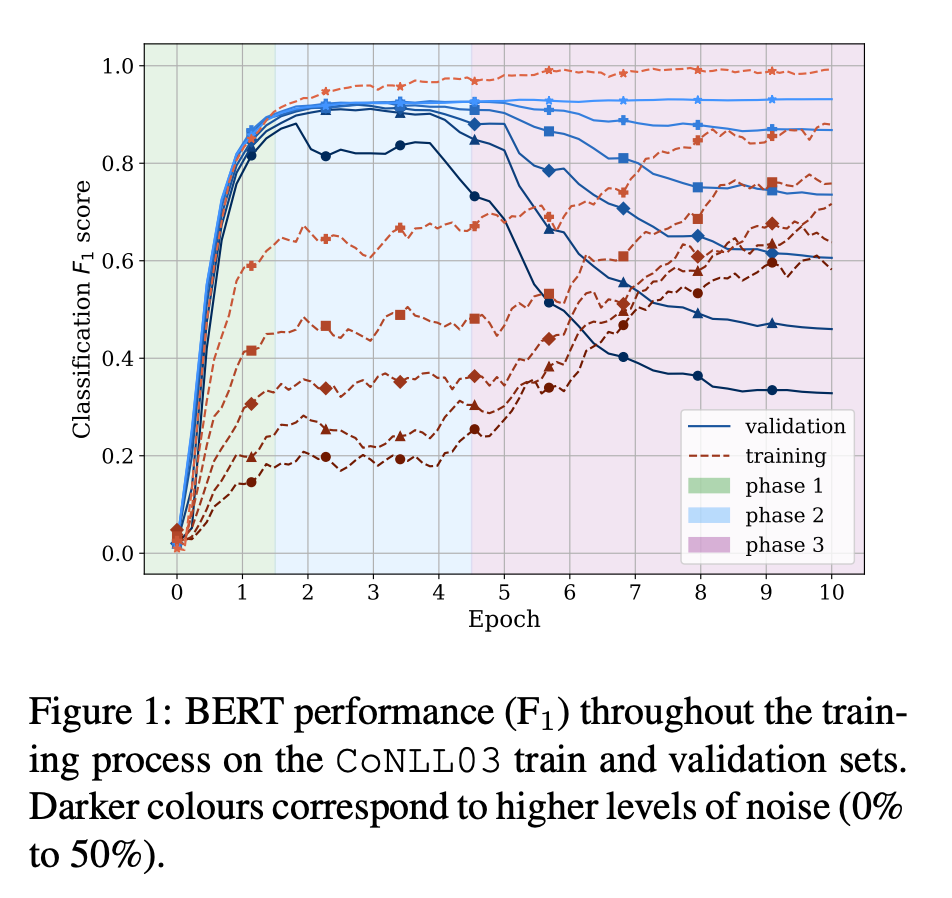
본 논문은 Pre-trained LM이 Fine-tuning 될 때의 학습 프로세스를 Generalization과 Memorization 관점에서 탐구합니다. 실험 결과, 학습 데이터셋의 레이블이 상당 부분 훼손되어있어도 BERT가 Near-optimal한 성능에 도달할 수 있음을 확인했고, 이러한 능력은 Fitting, Settling, Memorization의 3단계 학습 과정에서 비롯된다는 것을 발견했습니다. 또한, 학습 Example의 개수가 Memorization 및 Generalization에 큰 영향을 주고, BERT가 Few-shot 세팅에서는 학습에 어려움을 겪는다는 사실을 발견했습니다. 본 논문에서는 Low-resource 세팅에서도 충분한 성능을 달성할 수 있는 ProtoBERT를 제안하였고 실험을 통해 해당 모델의 유효성을 검증했습니다.
Multi-View Document Representation Learning for Open-Domain Dense Retrieval
작성자: 이봉석
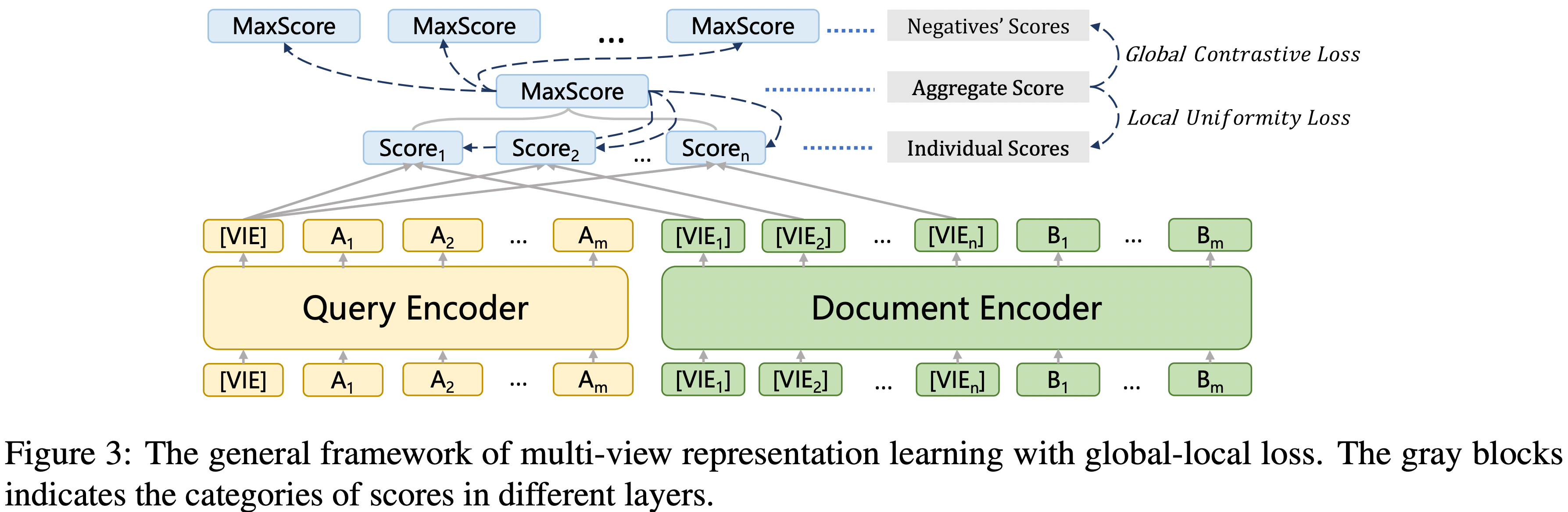
Open-domain Retrieval Task에서 Query에 적절한 Document를 검색하기 위해서 Dense Retriever를 많이 활용합니다. 하지만 Document와 Query는 1대1로 매핑되는 것이 아니고 하나의 Document에 대해 여러 개의 Query가 매핑됩니다.
논문의 저자들은 Document의 여러 측면을 표현하기 위해 Multi-view Embeddings을 생성하고 다른 Query들에 대한 Align을 강제하는 Multi-view Document Representation Learning Framework를 제안합니다. 먼저, 간단하지만 효과적인 방법을 통해 Multiple Embeddings을 생성합니다. 그 다음 Multi-view Embeddings이 동일한 것으로 학습되는 것을 방지하기 위해 다른 의미론적 Views에 잘 Align되도록하는 Global-local Loss를 제안합니다. 3가지의 Open-domain Retrieval Datasets에 대한 실험에서 기존의 SOTA 모델들보다 높은 성능을 보였습니다.
Contextual Representation Learning beyond Masked Language Modeling
작성자: 고상민
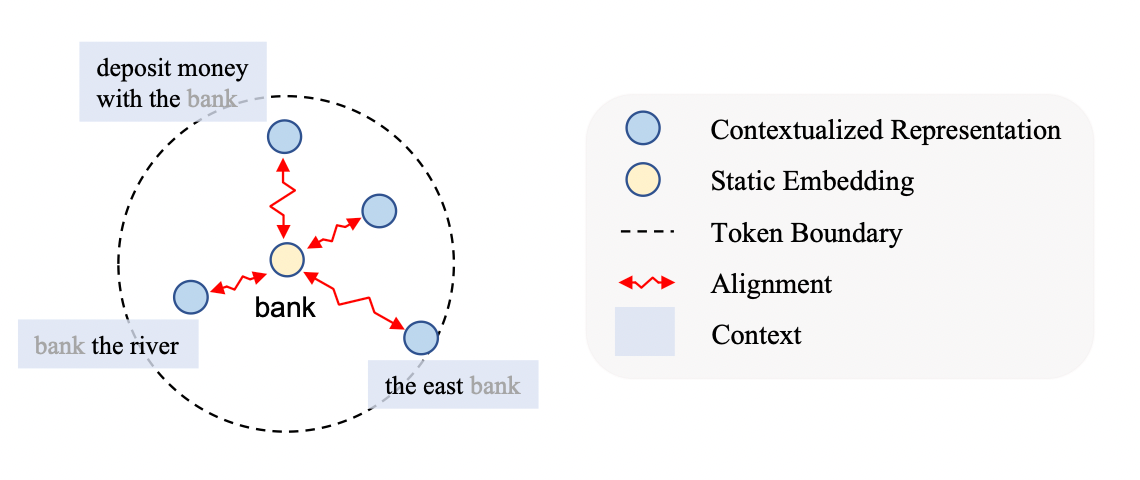
BERT와 같은 Masked Language Model (MLM)이 Contextual Representation을 어떻게 배우는지 연구한 논문입니다. Pre-training 과정에서 Intra-context Similarity를 측정하면 처음에는 감소하다가 일정 스텝이 지나면 다시 증가한다는 것을 볼 수 있습니다. 이는 MLM이 Local Context를 주로 배우기 때문에 Global Context에 대한 정보를 잃어버린다고 해석할 수 있습니다. 이를 보정하기 위해 같은 Context 여부를 Contrastive Learning으로 같이 학습하는 Token-Alignment Contrastive Objective (TACO)를 제안하였습니다. GLUE 벤치마크에서 다른 MLM 기반 언어 모델에 비해 5배 더 빠르게 수렴하고 평균적으로 1.2점 더 좋은 성능을 보여주었습니다.
A Closer Look at How Fine-tuning Changes BERT
작성자: 서상우
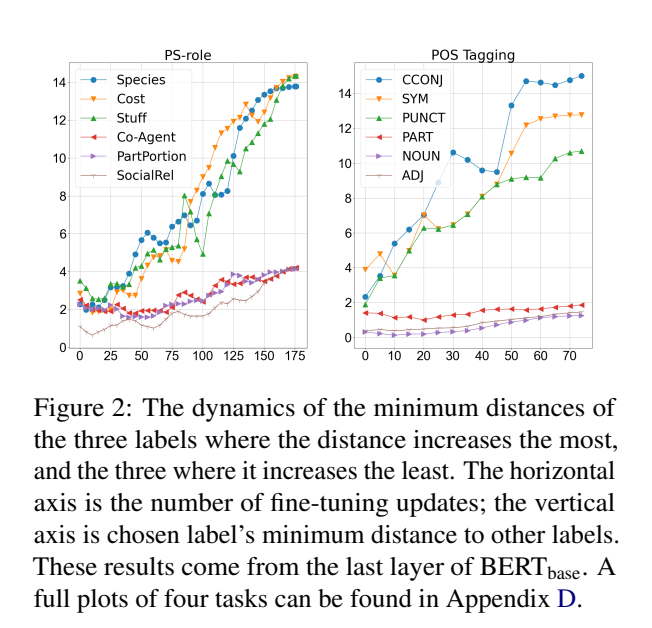
Fine-tuning시에 BERT의 Representation이 어떻게 변하는지를 다룬 논문입니다. 첫 번째로는 Performance에 관련한 실험을 진행했는데 Representation을 같이 Fine-tuning 하는 것이 Freeze하고 학습시키는 것에 비해 항상 좋다고 할 수는 없다고 합니다. 또한 Fine-tuning 전후로 Representation의 Cluster, Geometric Structure 등이 어떻게 변하는지를 봅니다. 결과적으로 Fine-tuning을 하면 Representation Cluster의 Center 개수가 줄며 Cluster 별로 거리가 멀어집니다. 또한 상위 레이어일수록 Fine-tune 시에 Geometric Structure의 변화가 더 커진다고 합니다.
Overcoming Catastrophic Forgetting beyond Continual Learning: Balanced Training for Neural Machine Translation
작성자: 박상준
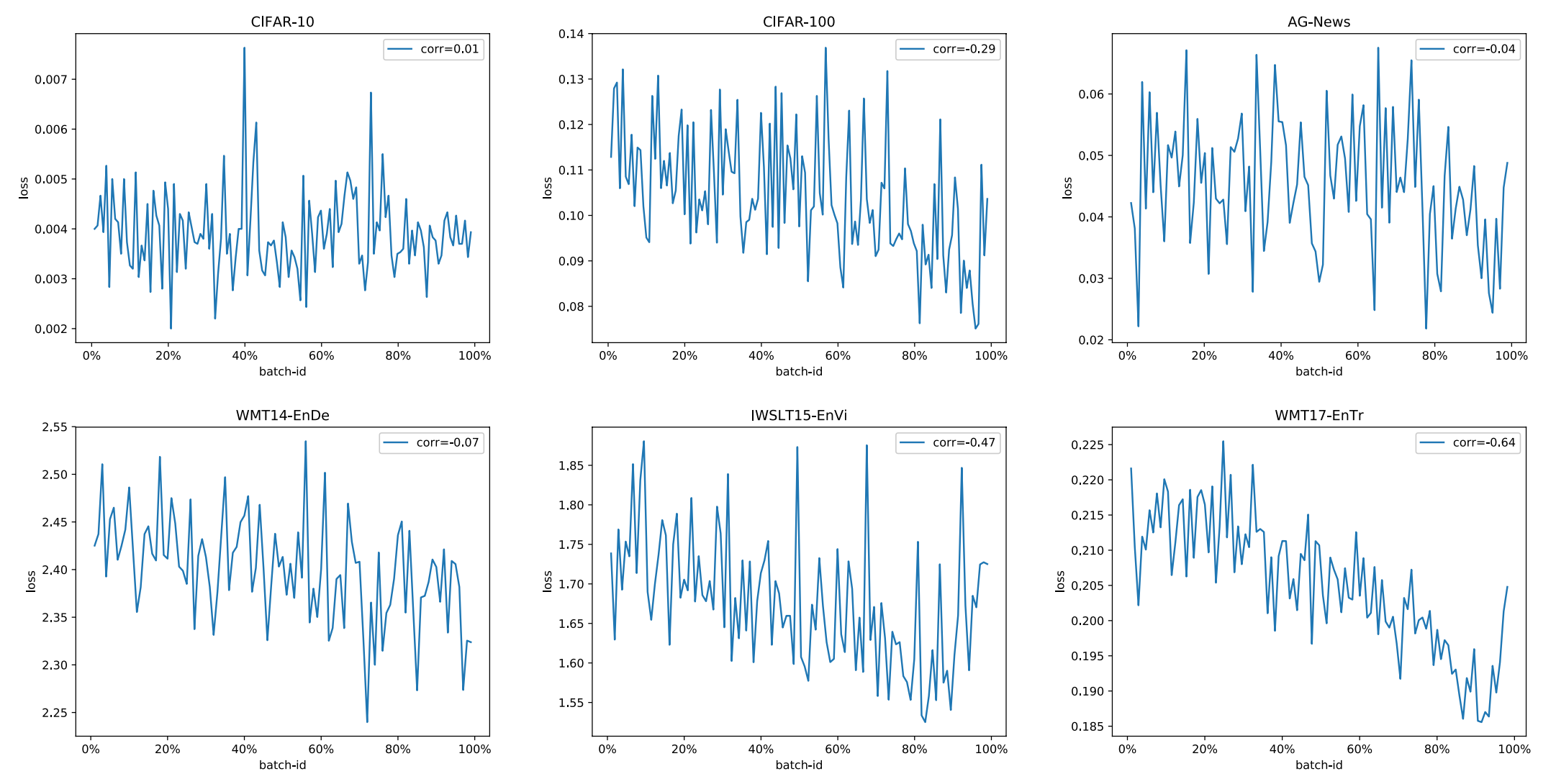
본 논문은 Continual Learning 뿐만 아니라 전통적인 Static Training에도 Catastrophic Forgetting의 영향이 있음을 밝히며, 특히 최종 모델은 이전에 학습한 샘플보다 최근에 노출된 학습 샘플에 더 많은 주의를 기울이고 있음을 지적합니다. 이를 검증하기 위해 저자들은 학습 데이터셋의 순서를 보존하여 학습을 진행하고, (1) 최근 학습한 데이터에 대한 Loss가 이전 데이터들보다 더 낮거나 (2) 초기에 학습했던 데이터보다 최근에 학습했던 데이터의 Attention Weight이 더 높은 경향 등을 근거로 밝힙니다. 본 논문은 또한 이를 해결하기 위한 Complementary Online Knowledge Distillation (COKD) 기법을 제안했습니다. COKD 기법은 순차적인 방식으로 데이터를 학습하는 것에 더해, 매번 다른 데이터로 학습된 Teacher 모델들로부터 Distillation도 함께 받으면서 학습하는 것으로 위 문제를 해결하며 성능을 개선할 수 있었습니다.
A Taxonomy of Empathetic Questions in Social Dialogs
작성자: 김수정
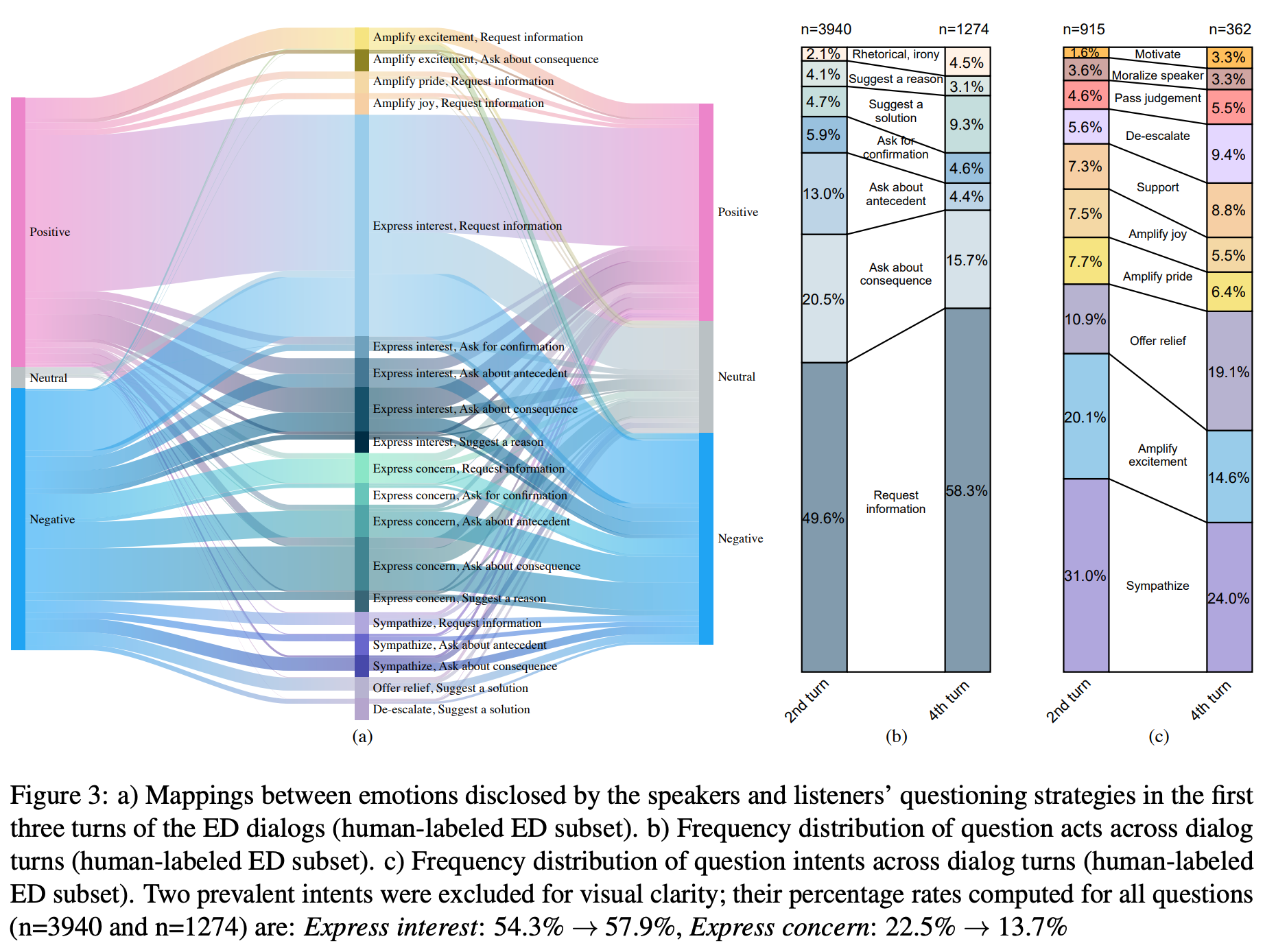
챗봇이 상대의 발화에 대해서 의미있는 공감성 질문을 하는 게 중요합니다. 상대의 감정에 대해 공감하고 궁금해하는 태도가 상대와의 깊은 관계를 맺는 초석이 되기 때문입니다. 공감성 질문을 생성하기 위한 키포인트는 공감성 질문의 의도를 잘 분류하는 것입니다. 그래서 본 논문의 저자들은 대화 중에 챗봇이 하는 공감성 질문의 의도를 분류하기 위해, 크라우드소싱으로 500개 대화에 대해 Dialog-Act (상대에게 질문을 통해 요구하는 액션), Dialog-Intent (질문하는 챗봇의 질문 의도)를 레이블링했습니다. 또한 이 데이터로 전체 셋을 레이블링하는 자동 레이블링 툴을 개발했습니다. 이렇게 나온 공감성 질문 분류 결과는 상대의 발화에 대해 좋은 감정 교류를 이끌어낼 수 있는 챗봇의 다양한 질문 행동 양상들에 대한 인사이트를 제공합니다.
Ditch the Gold Standard: Re-evaluating Conversational Question Answering
작성자: 고유미
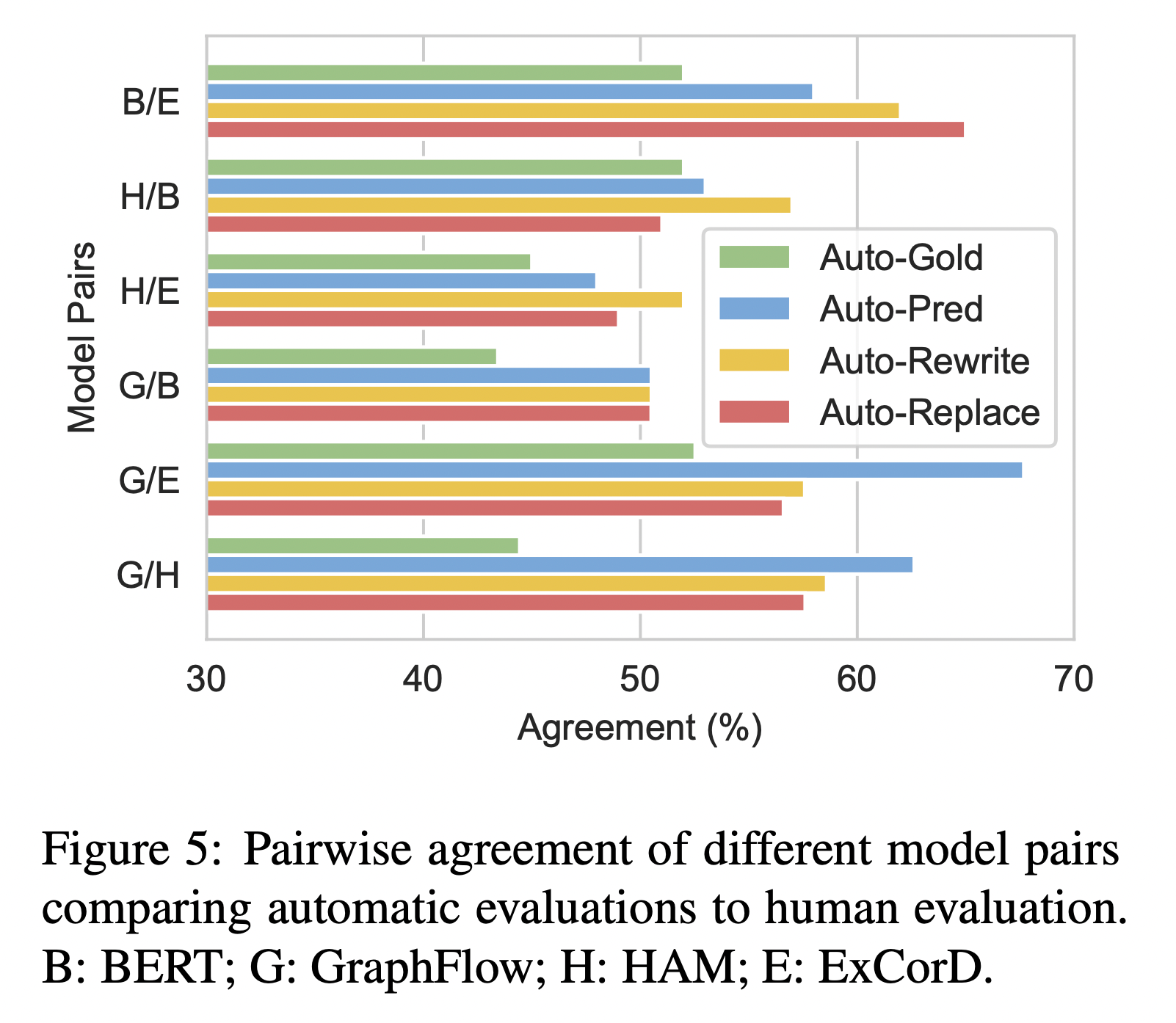
대화형 Question Answering Task에서 기존의 Gold History로 평가하고, Human-Human 대화와 비교하는 것이 적절한지 알아보고 개선하는 방법을 제안한 논문입니다. 이 논문에서는 Human-Machine 대화와 Human-Human 대화의 분포가 다르고, Gold History 평가와 Human Judgement 사이에 차이가 있다는 것을 보여줍니다. 또한, Gold History를 사용하면 이후 대화기록이 무효화되는 문제가 있기 때문에 Predicted History를 사용하고 해당 맥락에서 질문이 해결될 수 있도록 질문을 재작성하는 매커니즘을 고안하였고, 이것이 Human Evaluation과 더 일치한다는 것을 보여주었습니다.
VALSE: A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic Phenomena
작성자: 이재훈
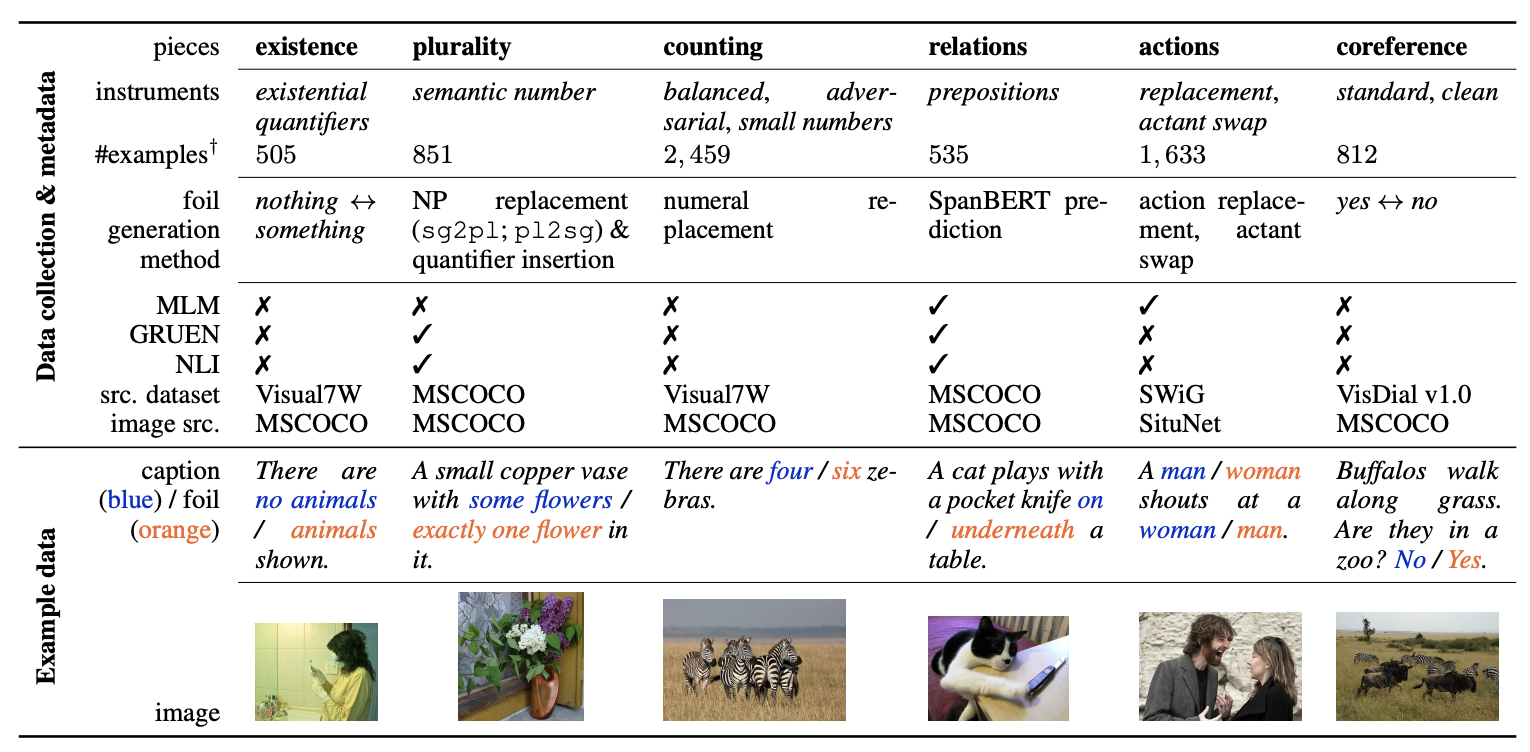
VLP 모델들은 현재 Downstream Task로 성능을 측정하고 있습니다. Image-Text Retrieval, Visual Question Answering 등 다양한 방법으로 VLP 모델의 성능을 측정하지만 근본적인 “Visual Language” 지능에 대한 평가는 없습니다.
본 논문은 Vision And Language Structured Evaluation (VALSE) 벤치마크 데이터셋 및 평가 방법을 제안하였습니다. FOIL (ACL 2017) 방법으로 Image-Text Pair에서 6가지 언어적인 구조에 조작을 가해 틀린 Pair를 만들고 VLP 모델이 잘 이해하는지 평가를 수행합니다. “Existence” 평가 결과에 따르면 VLP 모델들은 이미지 내 물체를 인식할 수 있고 물체가 이미지 안에 있는지 파악할 수 있지만, 이미지 내에서 객체들 사이의 상호 작용이나 관계의 의미를 이해하는 데 어려움이 있습니다. VALSE는 모델이 Fine-tuning 전후로 진짜 성능이 올랐는지 간접적으로 평가할 수 있는 좋은 데이터셋이 될 수 있어 보입니다.
What is wrong with you?: Leveraging User Sentiment for Automatic Dialog Evaluation
작성자: 송제인
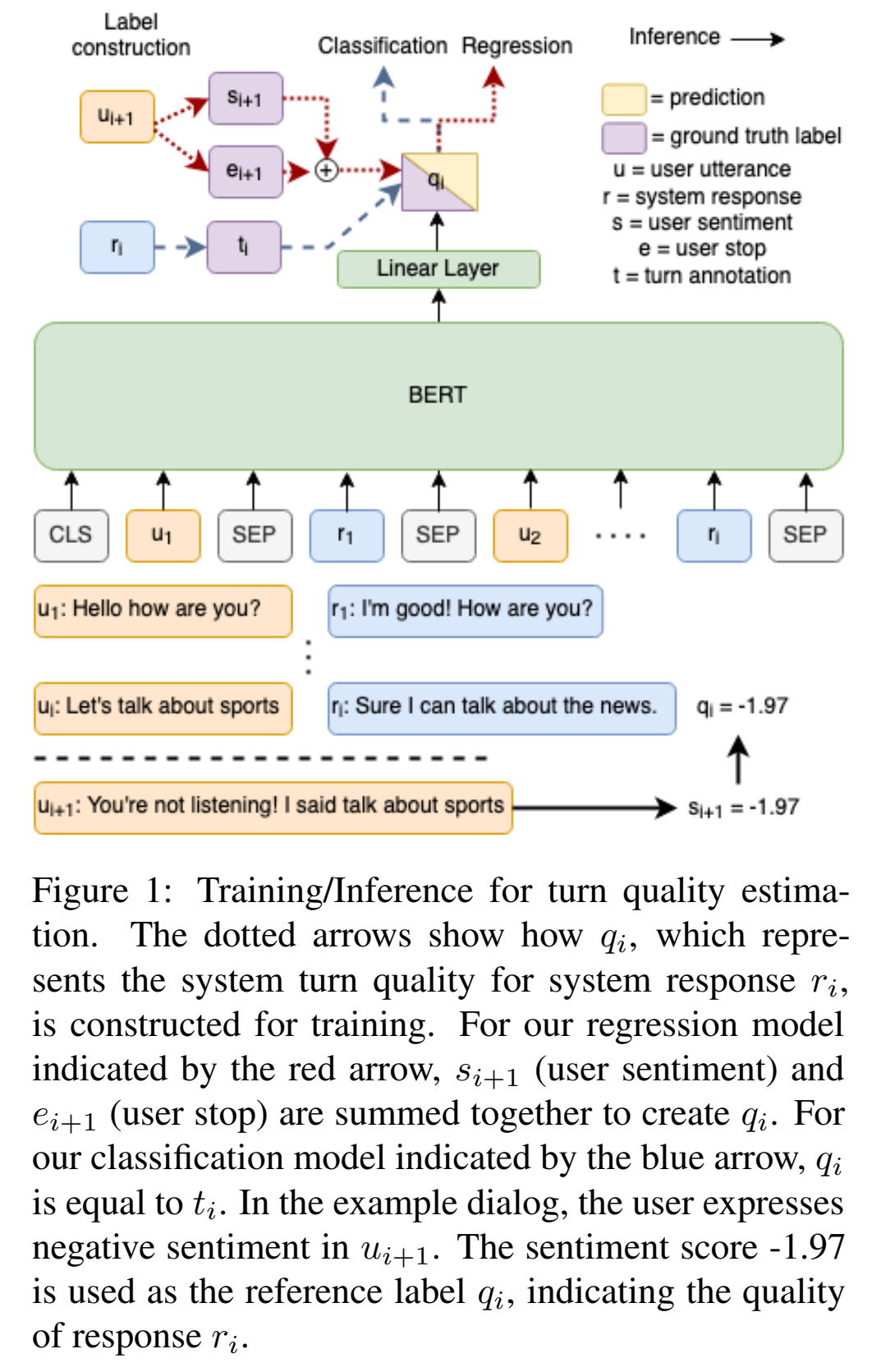
챗봇의 응답의 퀄리티를 자동으로 평가하기 위한 방법을 제안한 논문입니다. 응답의 퀄리티를 측정하기 위해 응답에 대한 유저 답변의 감정 점수 (Sentiment Score) 및 유저의 대화 중단 여부 두 가지를 고려합니다. 응답에 대한 감정 점수를 얻기 위해 기존 연구에서 공개된 모델을 사용하여 대량의 다이얼로그에 대해 태깅을 하였고, 이를 기반으로 퀄리티 측정 모델 (Weakly Supervised Fashion)을 학습하였습니다. 이러한 방식으로 학습된 답변 퀄리티 측정 모델이 사람이 직접 태깅한 것과 비교적 높은 상관성을 가지는 것을 보였습니다.
Debiased Contrastive Learning of Unsupervised Sentence Representations
작성자: 이주홍
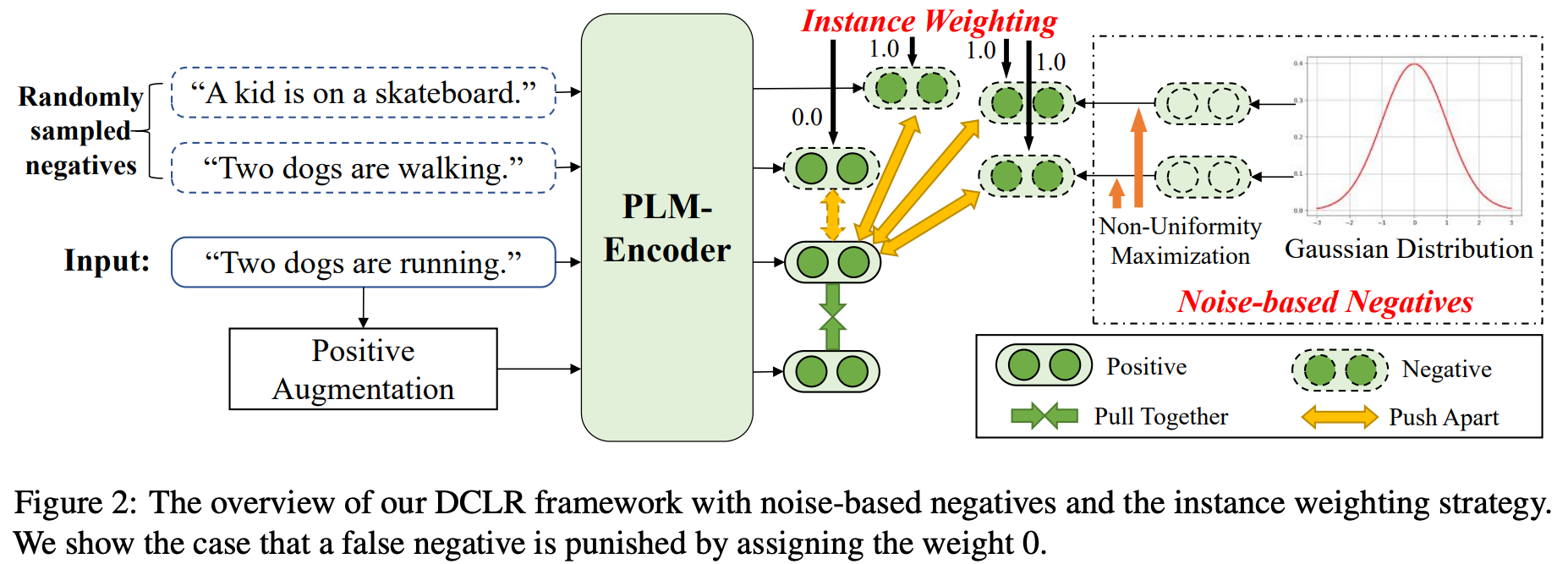
일반적으로 Contrastive Learning은 Negative Example을 얻기 위해 배치 내의 다른 Example (In-batch Negatives)을 활용하거나 학습 데이터로부터 Negative Examples를 샘플링합니다. 이때 두 가지 문제점이 있습니다.
- False Negatives: 실제 의미적으로 유사한 Example이 Negatives로 뽑히는 문제. 이는 Semantics을 파괴할 수 있습니다.
- Anisotropy Problem: Negatives의 Representation이 특정 영역에 쏠려서 Representation Space를 완전히 활용하지 못하는 문제. 이는 Representation Space의 Uniformity를 해칩니다.
본 논문은 Debiased Contrastive Learning of unsupervised sentence Representations (DCLR) 라는 프레임워크를 제안하였습니다. 구체적으로 False Negatives 중 Positive에 가까운 Example을 걸러내기 위한 Instance Weighting 기법과, 가우시안 분포에서 샘플링한 Negatives로 Noise-based Negatives를 활용하는 기법을 통해서 위의 두 문제를 완화시켰습니다. STS 태스크에서 SOTA 성능을 달성하였고 Representation Space의 Uniformity도 상당히 개선을 시켰습니다.