알라꿍달라꿍의 대화요약 이모저모
2021 한국어 인공지능 자연어 경진대회 대화요약 수상기

저(박상준), 최기원, 오혜린 셋은 작년에 열렸던 2021 한국어 음성·자연어 인공지능 경진대회에 함께 팀을 이뤄 대화요약 부문에 참가했습니다. 회사에서 공식적으로 참가한 건 아니지만 자주 보면서 이야기를 나눠야 하다 보니 자연스레 회사 동료들과 함께 참가하게 되었습니다. 대회 기간 내내 다같이 열심히 노력한 끝에 대화요약부문 1등으로 네이버 대표상을 수상🏆할 수 있었습니다. 이 글을 통해 저희가 어떤 식으로 대화요약 모델을 개선해나갔는지 공유하고자 합니다. 저희의 모든 실험과 아이디어를 기록한 건 아니지만 추후 대화요약 모델을 개발하실 분들께 도움이 되길 바랍니다.
목차
팀 소개
팀원소개

대회에 참가하게 된 계기를 설명하면, 원래 저는 2021년 새해 목표를 세울 때 올해는 인공지능 모델 개발 대회에 참여해보고 싶다고 생각했습니다. 그런데 연말이 되도록 못하고 있다가 이 대회 공고가 올라왔습니다. 당시 열렸던 국내에서 가장 큰 인공지능 대회였기에 보고 바로 나가야겠다 생각하고 사람들을 모아 참가했습니다. 저를 포함한 팀원 모두 NLP에는 익숙했지만 요약 Task는 전혀 경험이 없던 터라 초반에 특히 고생을 했습니다.
팀명

알라꿍달라꿍
:여러 가지 밝은 빛깔의 점이나 줄 따위가 고르지 아니하고 촘촘하게 무늬를 이루어 몹시 어수선한 모양.
예시
- 원 세상에 저렇게 알라꿍달라꿍 요란한 옷을 어떻게 입고 다니니?
- 탱자는 푸르락누르락 대추도 알라꿍달라꿍 눈에 보이는 모든 열매에 가을빛이 역력하다.
저희 팀명을 알라꿍달라꿍으로 정했는데 “인공지능, 훈민정음에 스며들다” 라는 컨셉에 맞게 우리말 단어로 짓고 싶었고, 동시에 저희 팀을 잘 표현할 수 있으면서 어감이 좋은 이름을 선택하고 싶었습니다. 사전을 뒤져보다가 알라꿍달라꿍이라는 단어를 발견했는데 무늬가 고르지 않고 어우선하게 어울려 있는 모양이 개성이 강한 저희 팀원들과 잘 맞는 것 같아 결정하였습니다.
대화요약이란?
요약이란?
요약은 기본적으로 길이가 긴 텍스트에서 핵심만 짚어서 짧게 간추리는 일입니다. 장문의 텍스트가 있을 때 전부 다 읽고 직접 중요한 부분을 파악하고 이해하면 가장 좋겠지만 그건 시간과 리소스가 많이 필요합니다. ML 기술이 발달하면서 딥러닝 모델을 이용하여 요약문을 생성하는 Automatic Text Summarization을 많이 활용하고 있습니다.
기계적인 방식으로 텍스트를 요약하는 방법은 크게 중요한 문장을 뽑아내서 배열하는 추출 요약(Extractive Summarization)과 텍스트를 이해하고 핵심적인 내용을 직접 생성해서 요약물을 작성하는 추상 요약(Abstractive Summarization)으로 나눌 수 있습니다.
Extractive Summarization
아래와 같은 글이 있을 때 Extractive Summarization은 핵심 문장들을 골라냅니다.
진리의 추구는 철학이 시작되고부터, 혹은 그 이전부터 시작됐다. 고대 아테네에서 활동했던 소피스트들은 진리의 회의주의, 진리의 상대주의를 주창했다. 절대적인 진리는 없고, 진리는 모두에게 상대적이라는 의미이다. 따라서 사실 진리나 생각 자체가 어떤 가보다는 타인에게 논파, 혹은 설득을 해냈는지가 중요한 것으로 여겨졌다. 그 때문에 사람들은 소피스트라는 그 시대의 선생님들에게 토론과 웅변을 배웠다. 그런 소피스트의 생각에 소크라테스는 반대했고, 결국 죽고 만다. 그리고 플라톤은 마침내 절대적 진리를 주장하여, 사람들에게 인정받는 데 성공했다. 이후에는 오랫동안 절대적인 진리의 시대였다. 그 대상은 고대, 중세 신의 시대, 이성의 시대를 거치는 중에 진리가 무엇인지 그 대상 자체는 계속 변해왔지만 항상 “모두가 따라야 할 절대적으로 옳은 무언가”가 있었다. 다시 말하면 모든 인간이 추구해야만 하는 올바른 목표가 시대 속에 주어진 세계였다. 그것을 잘 지키며 산다면 바람직한 삶으로 인정되었다. 그런데 세계대전이 두 차례 일어나고 인간의 존재를 너무 도구적으로 보는 시대에 대한 경각심 때문인지 감정의 중요성을 느낀 건지 그제야 인간은 의무를 벗어날 수 있었다. 한 명 한 명의 인간 자체를 중요시 여기고 존중하는 실존주의 시대에서 인간은 주어진 진리와 의무로부터 벗어났다. 만인 존중과 인권사상 속에서 인간은 자신의 삶을 선택할 수 있었다. 물론 그 와중에도 그러한 삶 자체가 하나의 패러다임을 이루기도 했지만 그럼에도 중요한 것은 어쨌든 의무적인 진리로 받아들여지지는 않는다는 점이다. 이제 절대적으로 옳은 것은 없다. 이 세계에선 저 사람의 의견이 나와 맞지 않아도, 저 사람이나 내가 틀렸다기보다는 그저 그와 나의 관점이 “다를” 뿐이다.
- 따라서 사실 진리나 생각 자체가 어떤 가보다는 타인에게 논파, 혹은 설득을 해냈는지가 중요한 것으로 여겨졌다.
- 다시 말하면 모든 인간이 추구해야만 하는 올바른 목표가 시대 속에 주어진 세계였다.
- 한 명 한 명의 인간 자체를 중요시 여기고 존중하는 실존주의 시대에서 인간은 주어진 진리와 의무로부터 벗어났다.
- 이 세계에선 저 사람의 의견이 나와 맞지 않아도, 저 사람이나 내가 틀렸다기보다는 그저 그와 나의 관점이 “다를” 뿐이다.
이렇게 원문에서 핵심적인 문장들을 선택해 배열하며 요약문을 만들어내는 방식이 Extractive Summarization입니다.
Abstractive Summarization
위와 같은 글이 있을 때 Abstractive Summarization은 원본 글을 토대로 내용을 파악하여 원래 원문 어디에도 없던 요약문을 생성합니다.
- 고대의 진리는 타인에게 설득을 할 수 있느냐였고, 중세 신의 시대나 이성의 시대에는 일반적이고 절대적인 진리가 있었지만 실존주의 사상이 보편화된 시대에서는 절대적인 진리란 없으며 서로의 생각을 존중하는 “관점”이 탄생했다.
Extractive vs Abstractive
| Extractive | Abstractive | |
|---|---|---|
| 장점 | • 항상 원본 문장을 가져오는 것이기 때문에 내용이 틀릴 가능성이 상대적으로 적다. | • 간결하고 유창한 요약문을 얻을 수 있어서 읽기 편하다. |
| 단점 | • 원래 글의 문장을 뽑아 그냥 이어 붙인 것이라 비교적 한눈에 보고 이해하기 어렵다. | • 모델이 직접 문장을 생성하기 때문에 실제와 다른 말이 요약문에 들어갈 수 있다. |
두 가지 방식은 이런 장단점을 가지고 있습니다.
대화 요약
“그럼 대화요약은 그냥 입력으로 문서 대신 대화를 넣으면 되는 거 아닌가?” 생각하실 수 있습니다.

하지만 대화는 문서와 달리 핵심정보가 보통 여러 화자의 여러 발화에 분산되어있는 경우가 많아 정보의 밀도가 낮습니다. 또 대화는 한 명의 작성자가 의도와 목적을 가지고 써내려가는 글과는 달리 두 명 이상의 화자가 자유롭게 말을 하기 때문에 본질적으로 예측하기 어려운 주제 전환이 잦고, 지시어의 사용이 많으며, 다양한 상호작용이나 화자들의 특성에 따른 특수한 어휘 사용이 많습니다. 위 그래프는 5년간의 세부 카테고리별 대화요약 논문 개수를 보여주는데 회의, 잡담, 의료 대화, CS, 이메일 등 대화라고 통칭하지만 세부 카테고리마다 대화의 목적이나 성격이 매우 다릅니다. 이런 점들 때문에 단순하게 문서요약과 같이 접근했을 때 어려운 점들이 있습니다.
Evaluation Metric
그러면 모델이 요약문을 만들었을 때 이게 얼마나 좋은 요약문인지를 무엇으로 판단할까요? 요약문의 품질을 판단하는 메트릭은 ROUGE-N, ROUGE-L, BLEU, BERTScore 등 다양한 방식이 있습니다. 하지만 이번 대회에서는 ROUGE-L 점수를 메인 평가 지표로 사용했습니다.
ROUGE-L은 두 문장의 LCS (Longest Common Subsequence)를 이용해 얼마나 유사한지 측정합니다.
$Reference:$ 나 아까 밥 먹었 어
$Hypothesis:$ 아까 점심 안 먹었 어 ?
만약 위와 같이 Reference와 Hypothesis가 주어졌다면
$LCS:$ 아까 먹었 어
이렇게 LCS를 얻을 수 있습니다.
$Precision: Length(LCS) \div Length(Hypothesis) = 3 \div 6$
$Recall: Length(LCS) \div Length(Reference) = 3 \div 5$
$F1: 2 \times Precision \times Recall \div (Precision + Recall) = 0.545454..$
그러면 LCS, Hypothesis, Reference의 길이를 이용해 ROUGE-L의 Precision, Recall, F1 점수를 계산할 수 있게됩니다.
대회 진행 세부사항
대회 데이터셋의 형태
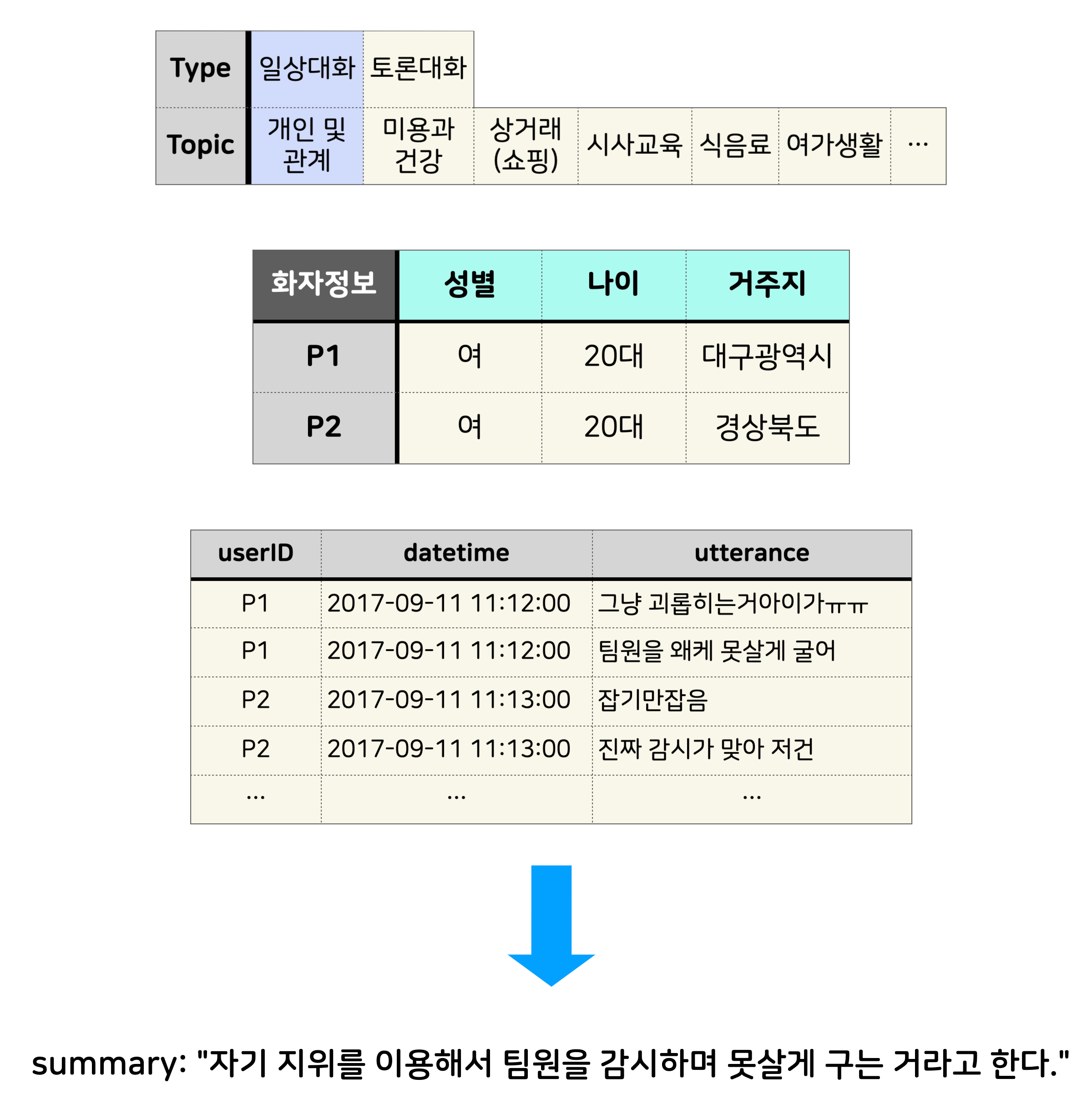
저희가 본선에서 사용한 데이터셋의 형태는 AIHub의 한국어 대화 데이터셋과 동일한 형식입니다. 화자와 발화시간이 포함된 대화 데이터가 있고, 모든 대화는 일상 대화와 토론 대화 중 하나로 분류되어 있으며 7종류의 대화 주제 중 하나가 명시되어 있습니다. 또한 화자들의 성별과 범주화된 나이, 거주지 정보가 포함되어 있습니다.
이 정보들을 이용해 적절한 요약문을 생성하면 됩니다.
대회 진행 방식
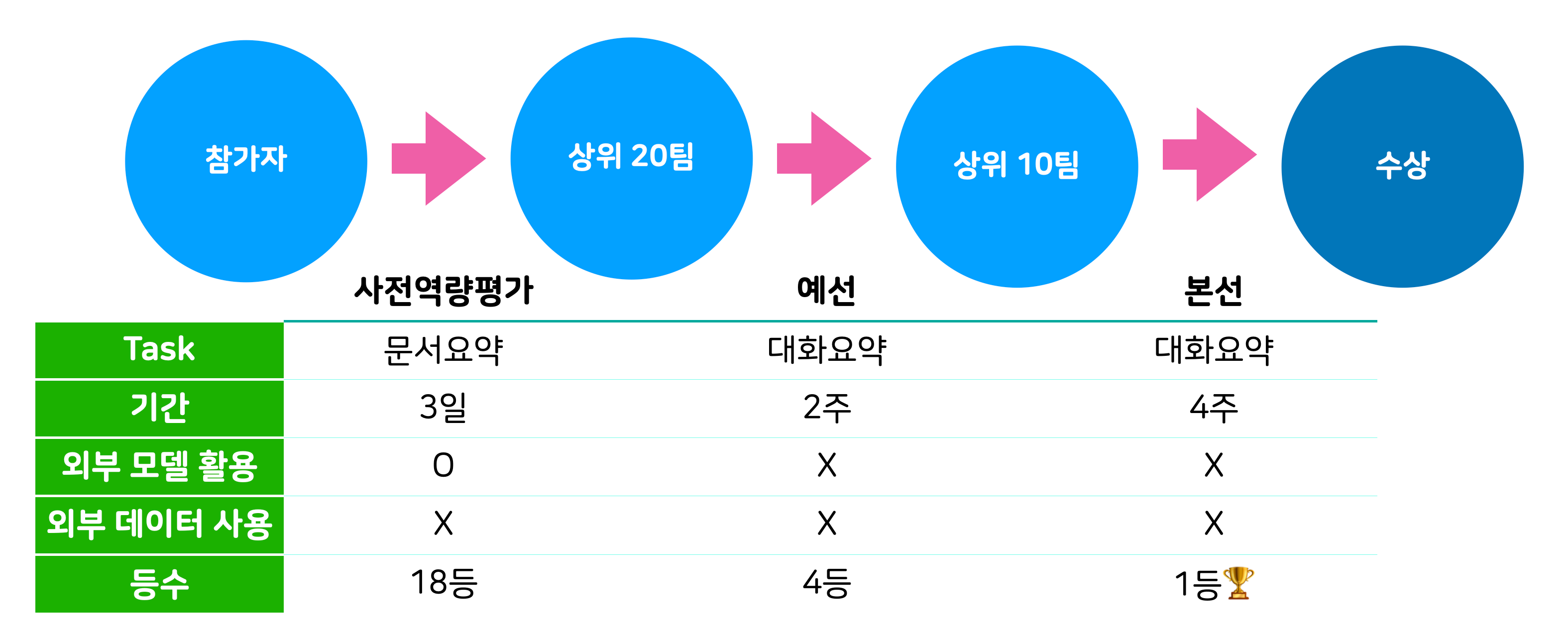
대회는 3번에 걸쳐 진행되었습니다. 사전역량평가에서는 문서요약으로 20팀을 선발하고 예선, 본선에서 대화요약으로 넘어가 각각 2주, 4주 동안 모델을 개발했습니다. 사실 저희는 사전역량평가가 가장 힘들었는데 우선 기간이 3일로 엄청 짧았고, 평일이라 퇴근 후에만 대회에 시간을 낼 수 있었으며, 저희는 모두 텍스트 요약 경험이 없었습니다. 또한 이때는 외부 모델을 활용할 수 있어서 누가 좋은 외부 모델을 잘 가져다 쓰느냐도 중요했는데 이 부분이 약했던 것 같습니다. 그래도 통과하여 예선 본선에서는 생각보다 순조롭게(?) 상위권에 올랐습니다.
Baseline
Tokenizer
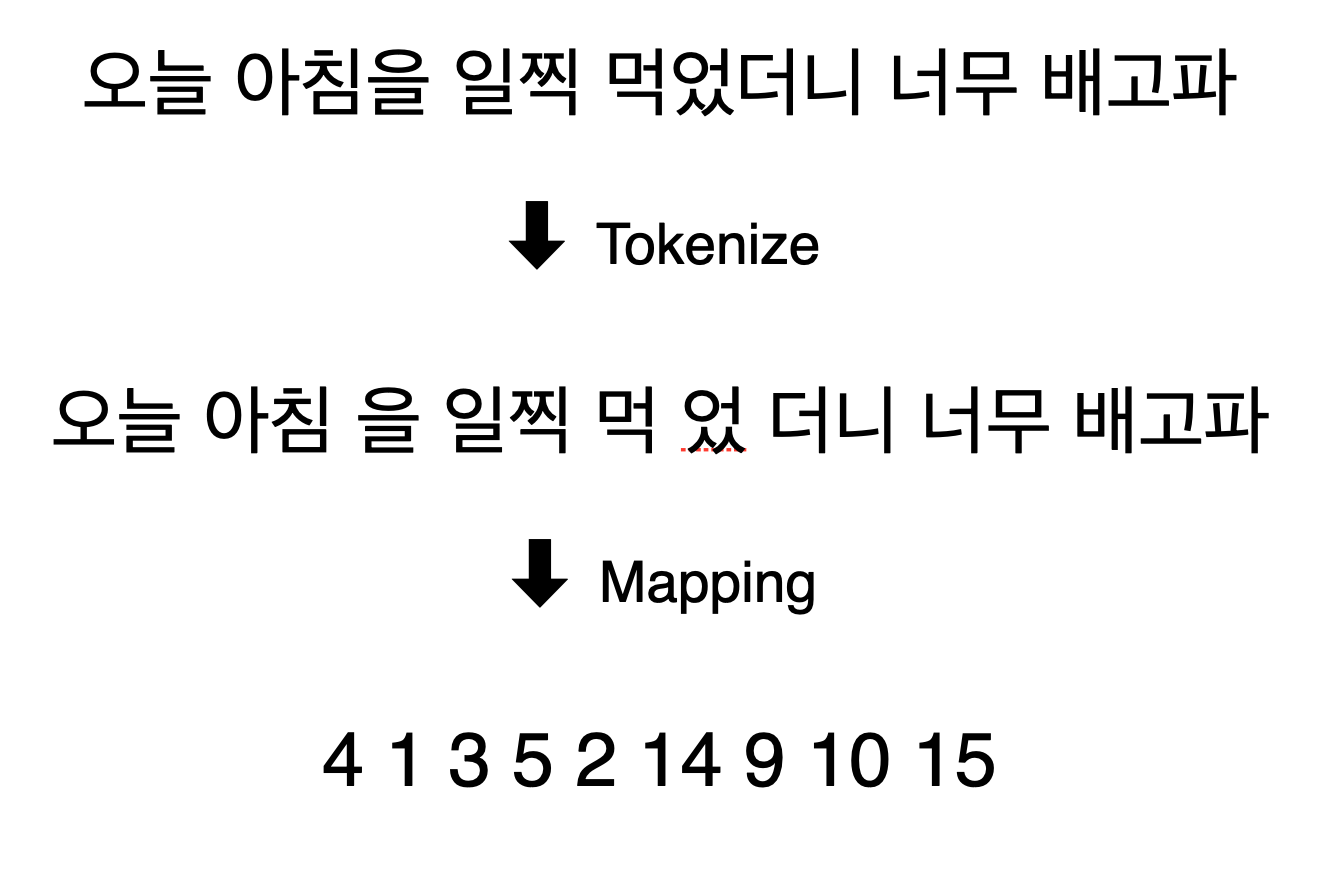
위와 같이 텍스트를 분절하여 모델에 입력으로 줄 수 있는 토큰으로 만들기 위해서 토크나이저가 필요합니다.
토크나이저는 외부데이터로 학습한 토크나이저나 사전학습된 토크나이저를 사용하는 게 규정상 가능했습니다. 저희는 자체 토크나이저를 학습하기 위해 사전학습된 외부 형태소 분석기인 mecab을 사용하였으며 입력 문장들을 분절하는 토크나이저는 추가적인 데이터 없이 대회 데이터만을 이용해 직접 학습해 사용했습니다.
일반적으로 좋다고 알려진 Unigram (Sentencepiece) 방식으로 학습해서 사용했으며 한국어 토크나이저를 학습할 때는 바로 학습하기보다 형태소 분석기로 1차 분절 후에 Subword 토크나이저를 학습시켜 활용하는 게 더 좋다는 연구에 따라 mecab으로 각 문장을 분절해서 토크나이저를 학습하였습니다.
Data Loader
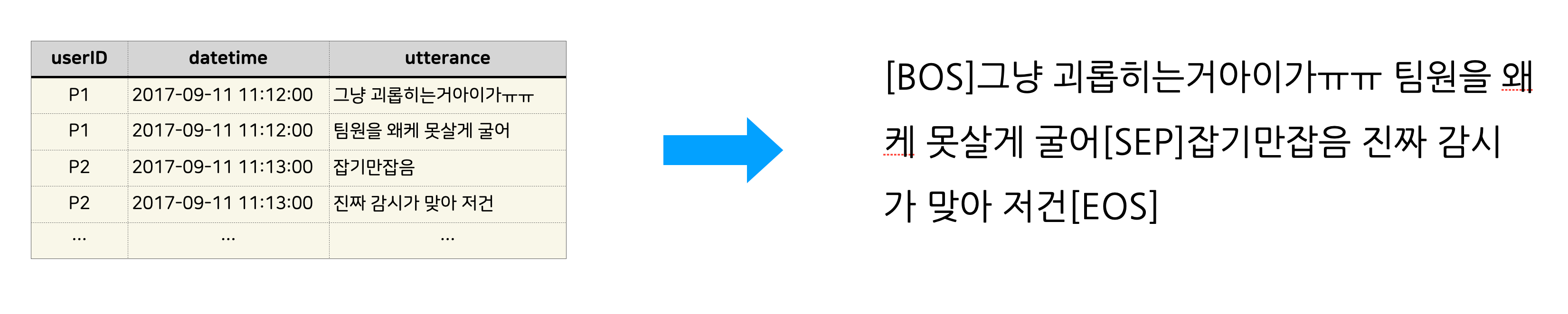
데이터에 대화 내용 외에도 화자, 시간 등이 포함되어 있는데 Baseline에서는 전부 고려하지 않았습니다. 다만 동일 화자의 연속발화는 띄어쓰기로 합쳤고 각각의 대화는 [SEP] 토큰으로 합쳐서 사용했습니다.
데이터를 보면 대화의 화자가 2명보다 많은 경우도 더러 있었는데 이 경우 위와 같이 표현하면 화자가 바뀌었다는 것만 알 수 있고 누가 말했는지는 알 수가 없게 됩니다. 그럼에도 데이터의 대화 내용과 요약문을 봤을 때 요약문을 생성하는데 화자의 구분이 크게 중요하지 않아보여 과감히 생략했습니다.
Architecture
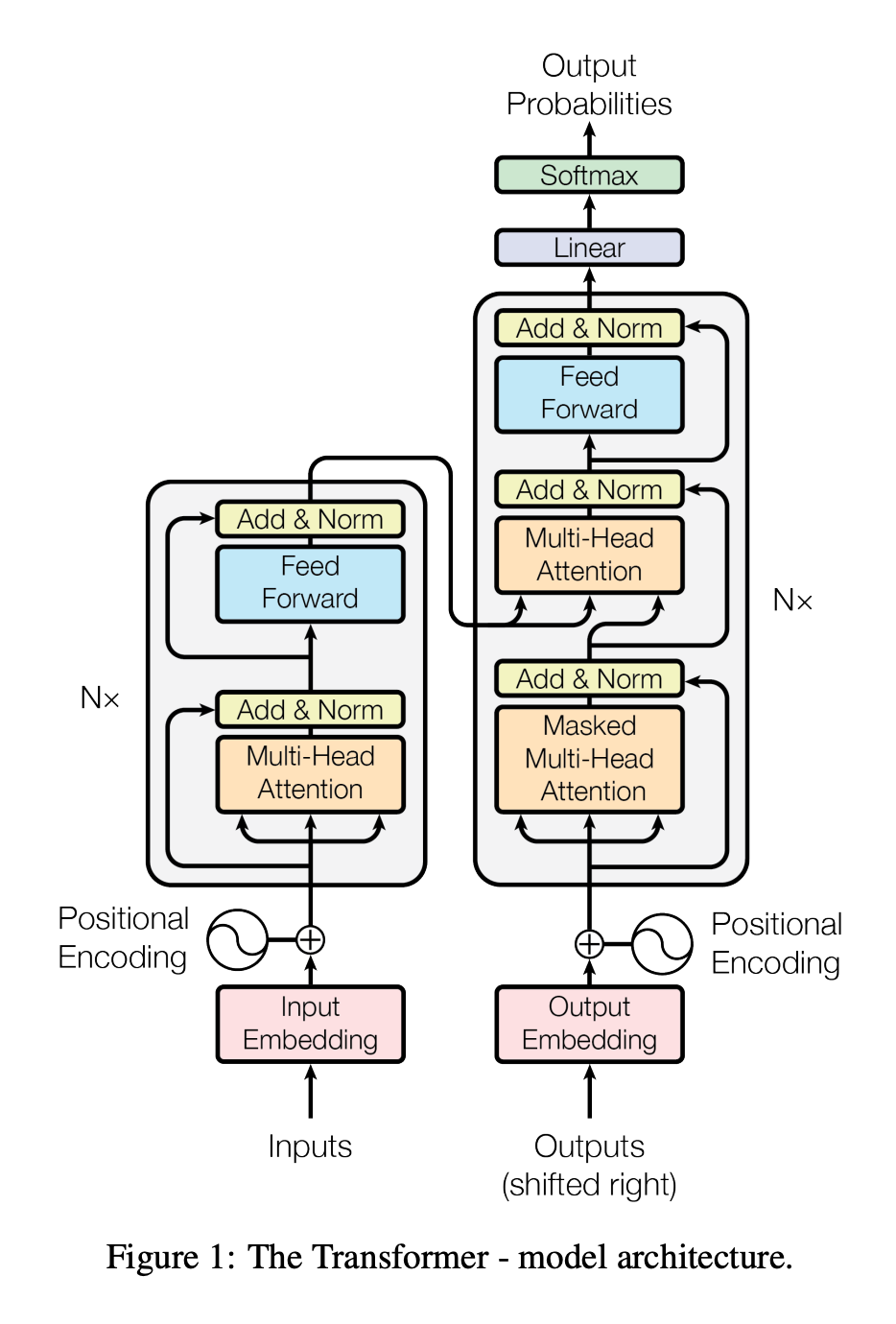
모델 Baseline은 각종 Abstractive Summarization 벤치마크에서 높은 성능을 보이며 많이 사용하는 Encoder-Deocder 구조의 모델 Transformer를 사용합니다.
실 구현체는 huggingface BART를 사용했습니다.
예시
Encoder Input: [BOS]그냥 괴롭히는거아이가ㅠㅠ 팀원을 왜케 못살게 굴어[SEP]잡기만잡음 진짜 감시가 맞아 저건[EOS]
Decoder Input: [BOS]자기 지위를 이용해서 팀원을 감시하며 못살게 구는 거라고 한다.[EOS]
실험
Pretraining
Text Infilling
최근 NLP에서는 일반적으로 Transformer 기반의 모델의 경우, 많은 Unlabeled 데이터로 사전학습한 뒤에 원하는 Downstream Task를 finetune해서 사용합니다. 하지만 저희는 대회 규정상 외부 데이터는 전혀 사용할 수 없었죠. 고민을 하다보니 이런 생각이 들었습니다.

소량의 Task Specific 데이터를 이용한 사전학습이라도 Denoising Task가 데이터의 특성을 이해하는 데에는 도움을 주지 않을까?
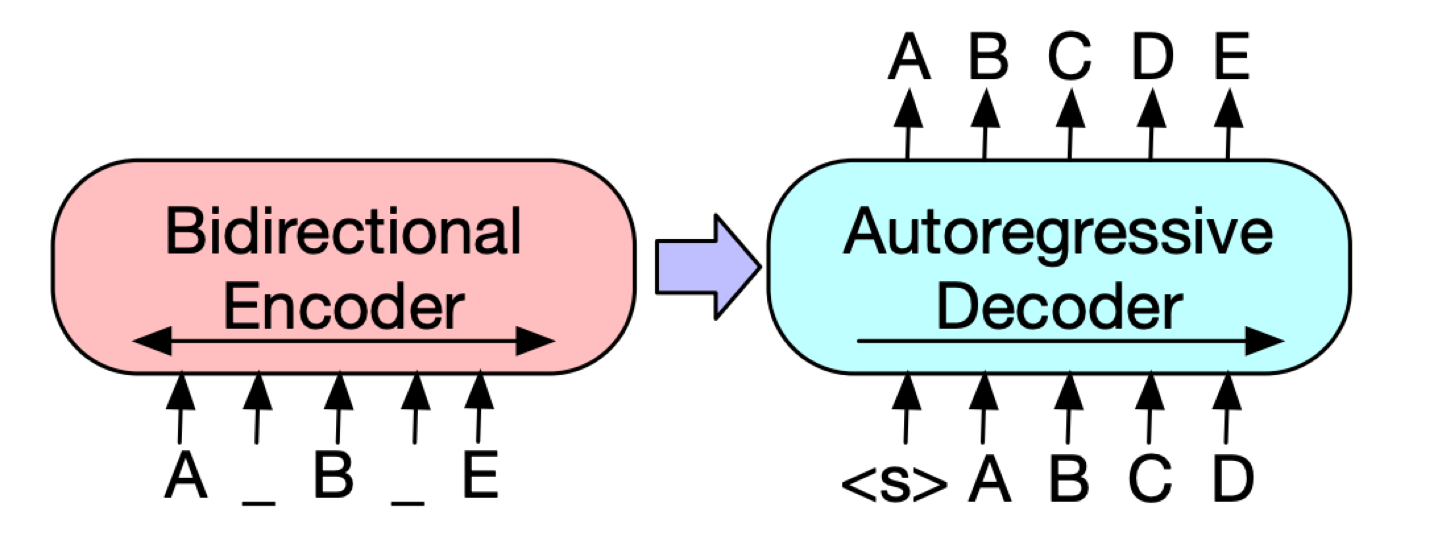
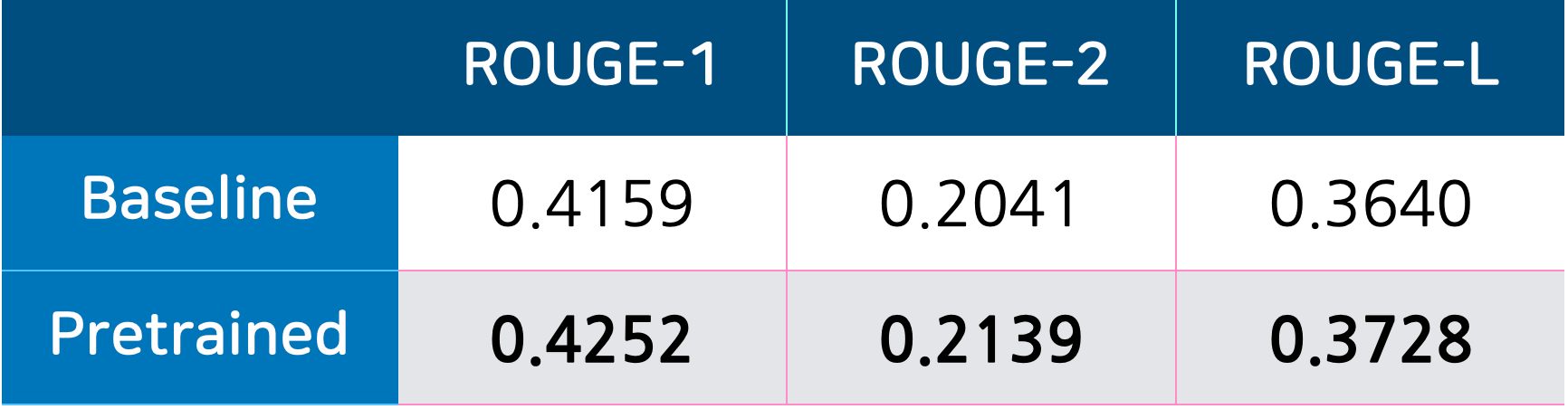
실험했을 때 유의미한 성능향상이 있었습니다.
Random Sampled Dataset
되긴 되는데 역시 다운스트림 데이터로만 사전학습 하는 건 효과가 너무 미미한 것 같은데 외부데이터는 못 쓰고… 다른 방법 없나? 전에 랜덤 데이터로 BERT 만드는 논문 있던 거 같은데 그거 한 번 볼까?
Pre-Training a Language Model Without Human Language
논문에서는 코드, 외국어, 아미노산, 프로그래밍 언어 등 다양한 데이터로 사전학습을 진행하는데 이중에서 Artificial이라고 랜덤한 토큰을 특정 규칙으로 생성해서 만든 데이터셋이 있습니다.
Artificial 데이터셋은 다음과 같이 만들어집니다.
- 매 timestep $t$마다 $X_t$를 이항분포 $P(X_t = 1) = 0.4$로 뽑는다.
- 만약 $X_t$가 1이라면 토큰을 랜덤하게 뽑아 sequence에 붙이고 또 별도의 스택에 넣는다.
- 만약 $X_t$가 0이라면 스택에서 토큰을 하나 뽑아 sequence에 붙인다.
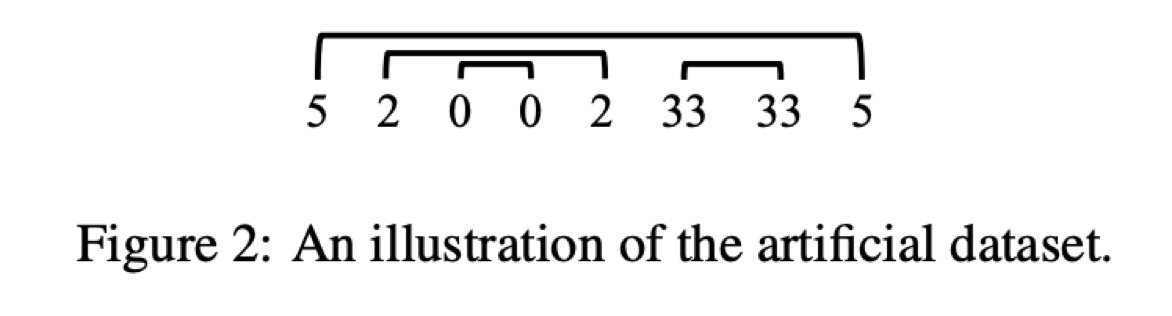
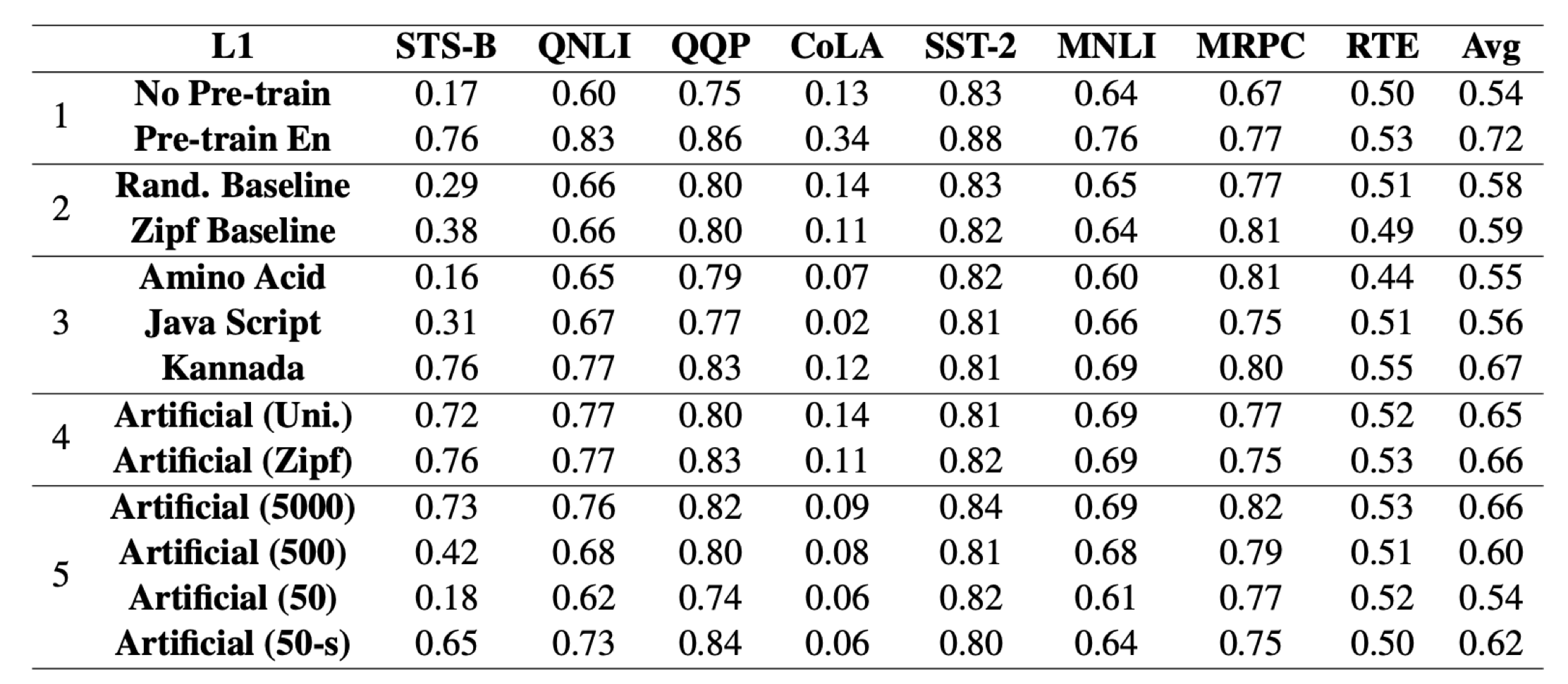
Artificial 데이터셋의 점수를 보면 그래도 No Pre-train과 비교했을 때 성능 상 유의미한 차이가 있어 보입니다.
Does Pretraining for Summarization Require Knowledge Transfer?
조금 더 찾아보니 심지어 랜덤 데이터로 Summarization Task를 Pre-train하는 논문도 발견했습니다.
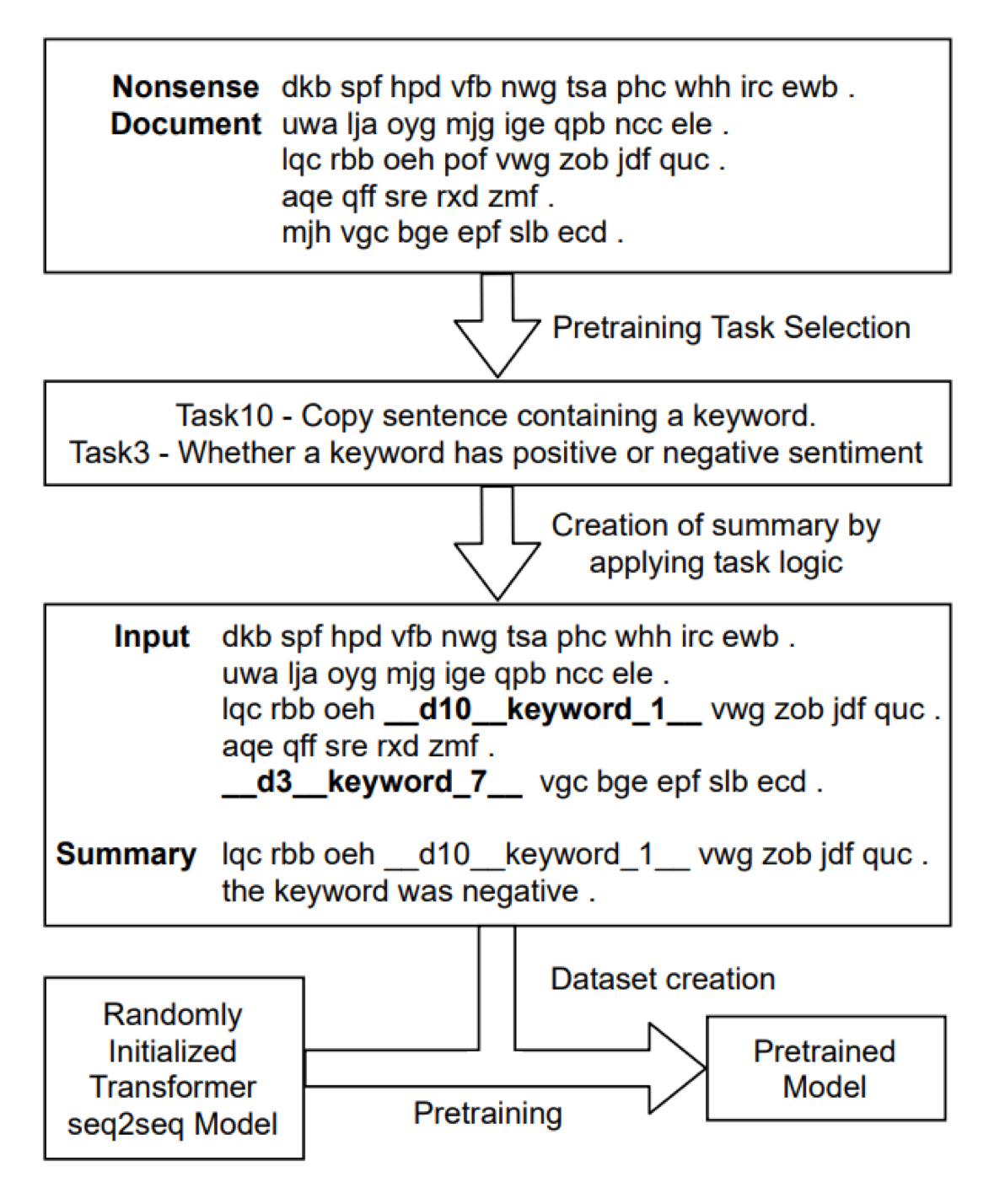
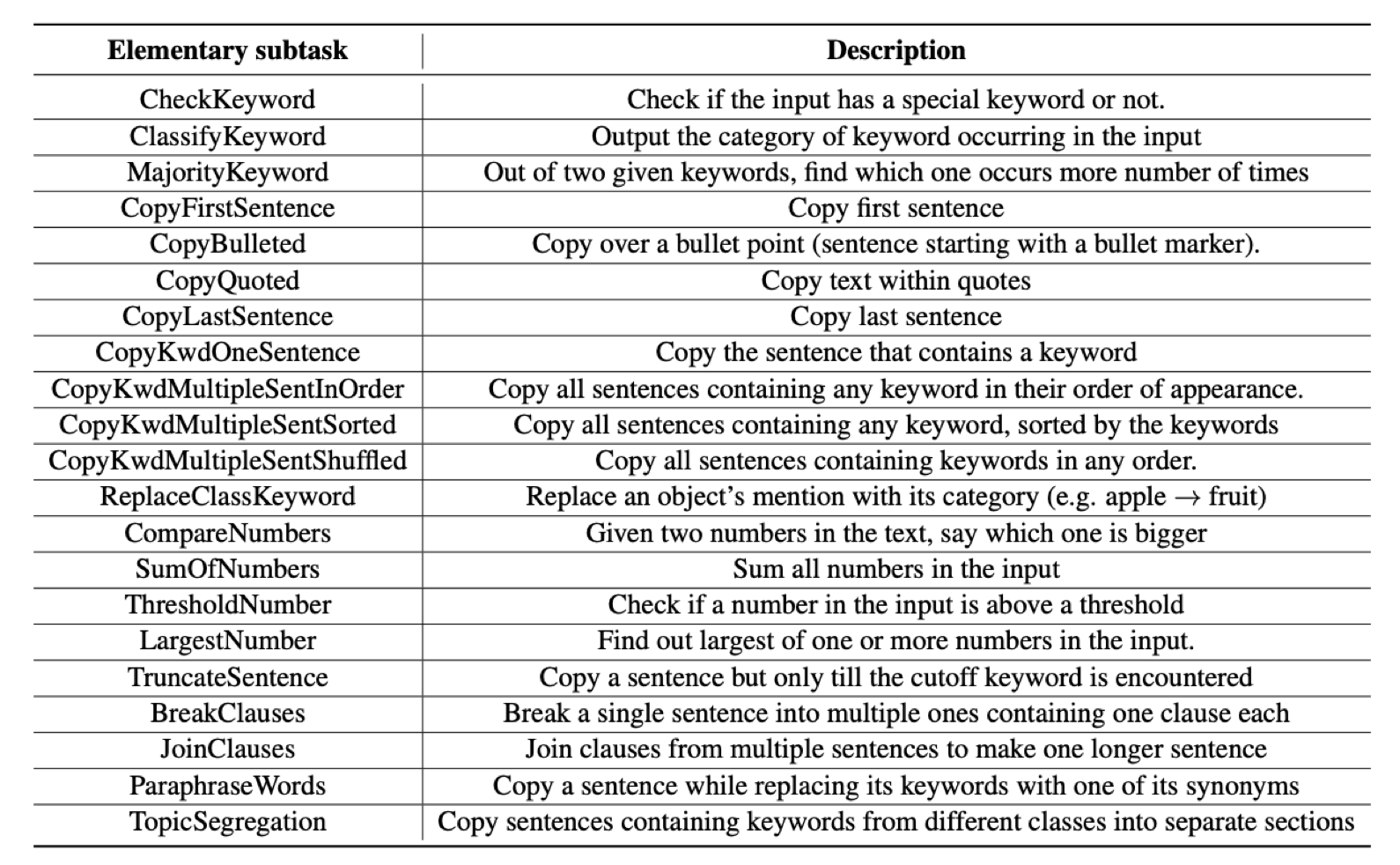
여기선 랜덤 데이터를 만들고 특정한 룰기반 Task들을 랜덤으로 골라 적용해서 Input과 Summary를 인위적으로 만들고 그걸 풀도록 학습시킵니다.
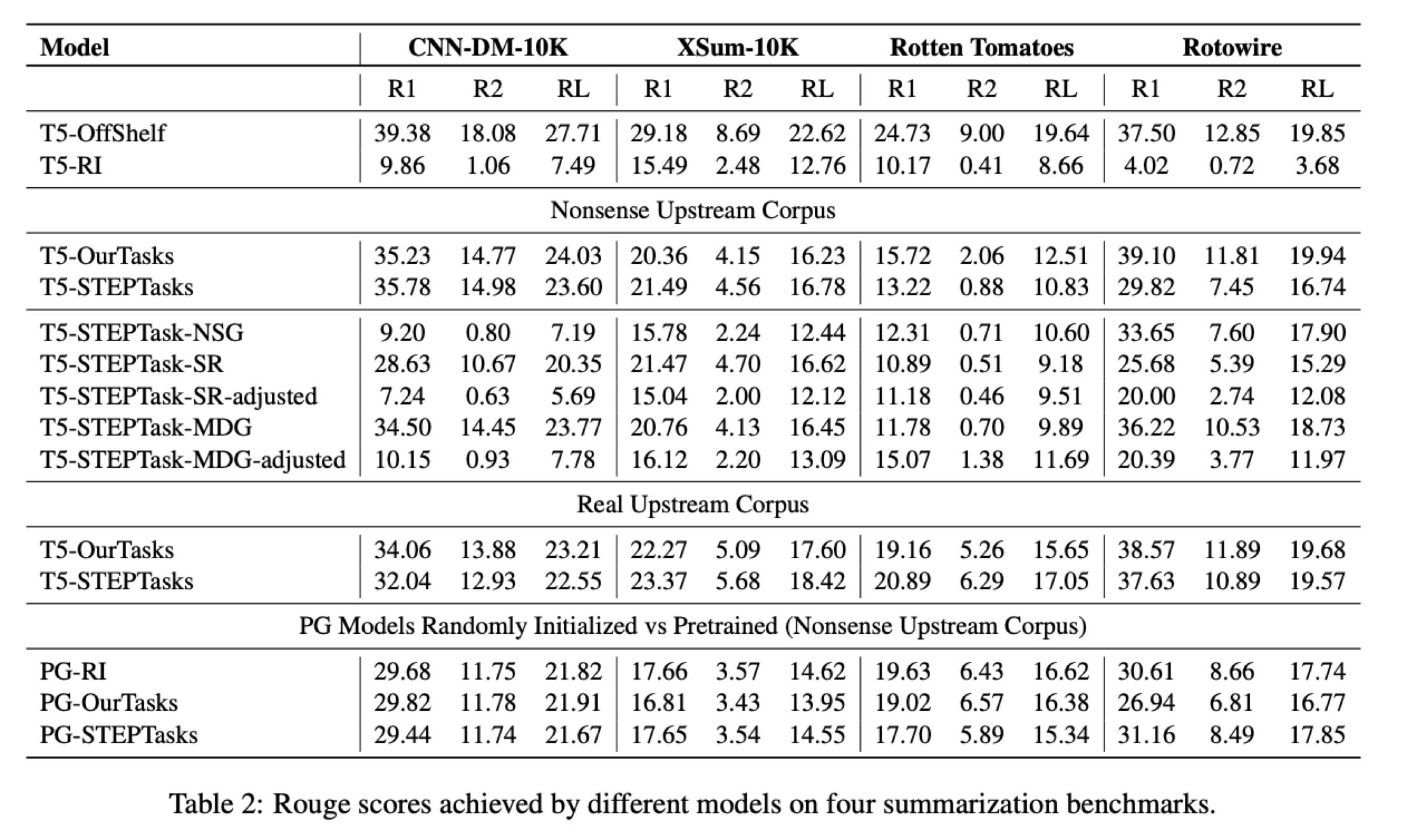
T5-RI 가 Random Initialized고 Nonsense Upstream Corpus가 랜덤으로 만든 데이터, OurTasks가 저자들의 방법론입니다. RI와 비교하면 도표 상으로는 대부분 랜덤 데이터로라도 학습을 시킨 게 더 좋아보입니다.
하지만 저희가 직접 해봤을 때는 RI보다도 성능이 훨씬 안 좋아서 사용할 수 없었습니다. 저 논문의 RI가 실제로 사용하는 좋은 Initialize 방법론을 따르지 않은 게 아닐까 의심이 들었지만 검증은 해보지 못했습니다.
Random Dialogue & Text Infilling
역시 랜덤은 무리수였나…? 데이터셋이 적지만 사실 발화만 보면 한 example당 5~10개는 있으니까 이걸 잘 조합해서 활용하면 풍부한 사전학습 데이터를 얻을 수 있지 않을까?
데이터셋 전체의 발화를 싹 다 모아서 랜덤하게 세션을 구성해보면 어떨까?
세션 내에서 발화 간의 관계에 대한 이해는 약해지겠지만 임의의 세션을 제한된 크기의 Embedding으로 표현하는 능력은 그래도 같은 데이터만 계속 보는 것보다 높아지지 않을까?
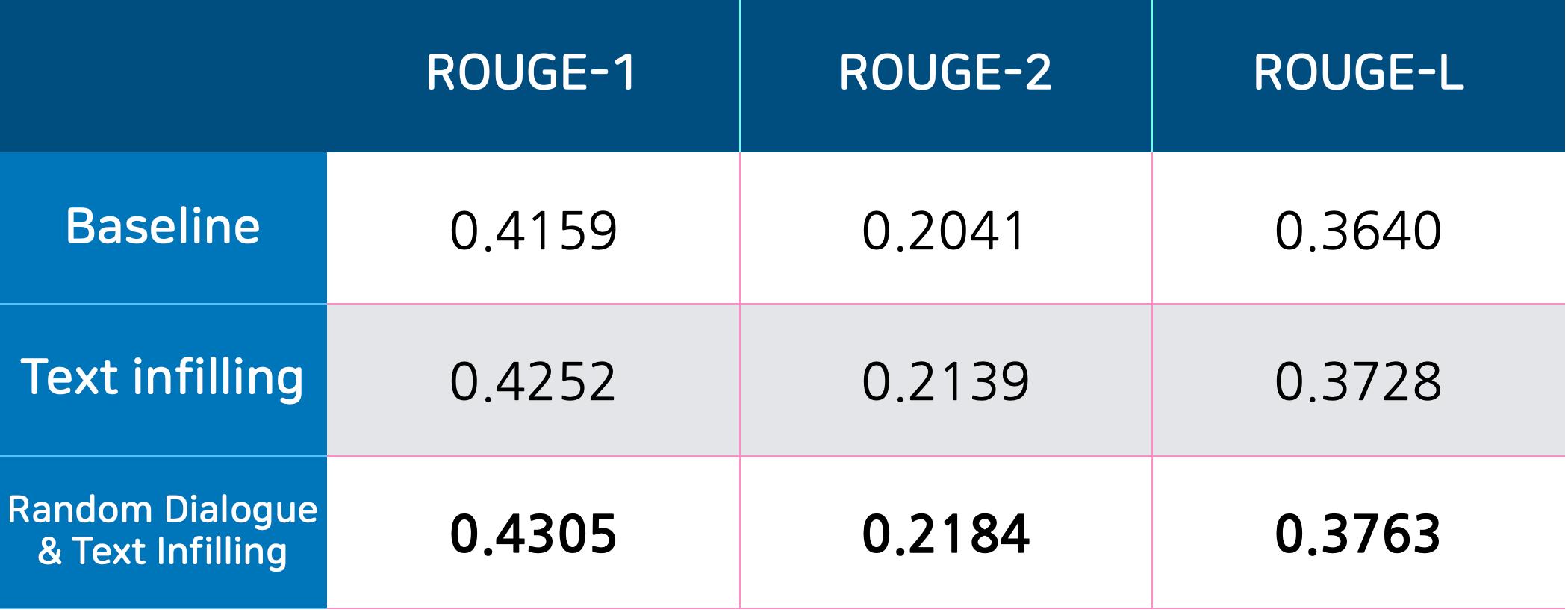
그리고 발화들을 랜덤으로 추출해 구성한 랜덤 Dialogue에 Text Infilling 했을 때 그냥 데이터로 학습했을 때보다 약간 더 높은 성능을 기록했습니다. (와우!)
Permutation & Token Masking
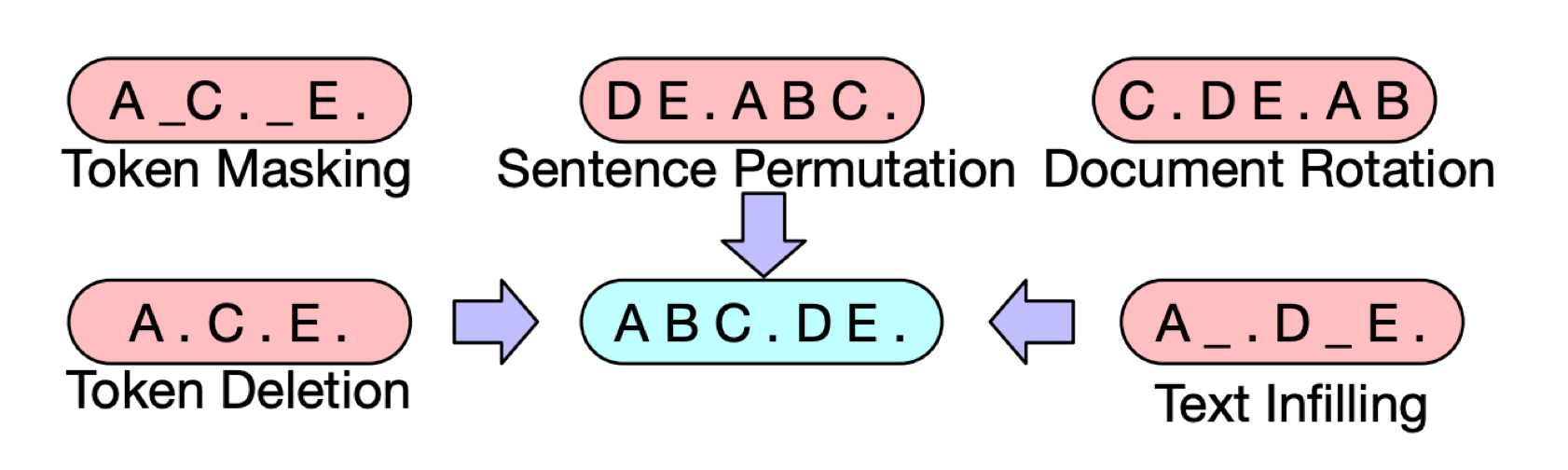
그런데 이후 최기원님이 BART의 방법론에서 Sentence Permutation을 Token Masking과 함께 적용해서 실험했을 때 Random Dialogue보다 약간 더 높은 성능을 보였습니다. 생각해보면 임의의 세션을 제한된 크기의 Embedding으로 표현하는 능력은 세션 내에서만 문장을 Permutation만 해도 충분했을 것 같습니다. 더불어 세션 내 발화 간의 유의미한 관계도 학습할 수 있죠.
Random Dialogue 방식은 임의의 문장을 섞는 것이라 세션 내의 문장들을 Permutation하는 Sentence Permutation과 함께 사용할 수 없기 때문에 이후 실험에서 사전학습 방법론은 Token Masking & Sentence Permutation으로 고정하였습니다.
Type & Topic 토큰 사용

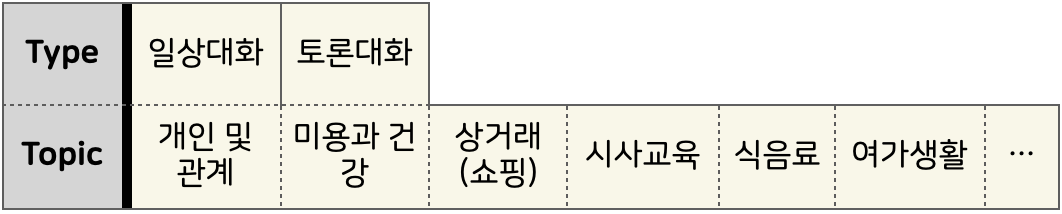

Type과 Topic 정보를 전혀 사용하지 않았는데 이 정보를 사용하면 더 요약문을 잘 만들지 않을까?
위 요약문은 실제 데이터는 아니지만 실제 데이터의 형태와 비슷한 형식으로 직접 작성한 것입니다.
데이터를 보면 Type이 토론 대화인 경우 “토론 한다”라는 서술어와 유의미한 관계가 있음을 볼 수 있습니다.
Topic은 봤을 때 엄밀하지는 않지만 그래도 사람이 단 만큼 큰 경향을 보면 일관성이 있지 않을까 생각해보았습니다.
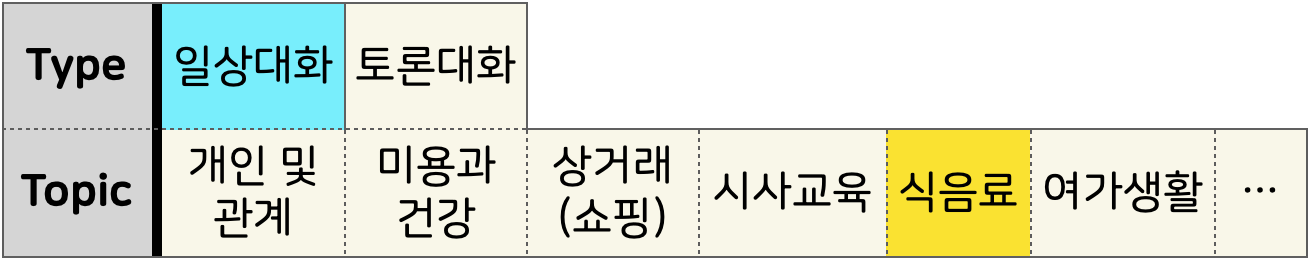
[BOS] 나 밥을 안 먹어서 너무 배고파 [SEP] 나는 배불러서 졸린데? 집에 갈래 [EOS]
→ [일상대화] [식음료] [BOS] 나 밥을 안 먹어서 너무 배고파 [SEP] 나는 배불러서 졸린데? 집에 갈래 [EOS]
먼저 가장 간단하게 Type 정보와 Topic 정보를 각 종류마다 특수토큰으로 만들어서 넣어주었습니다.
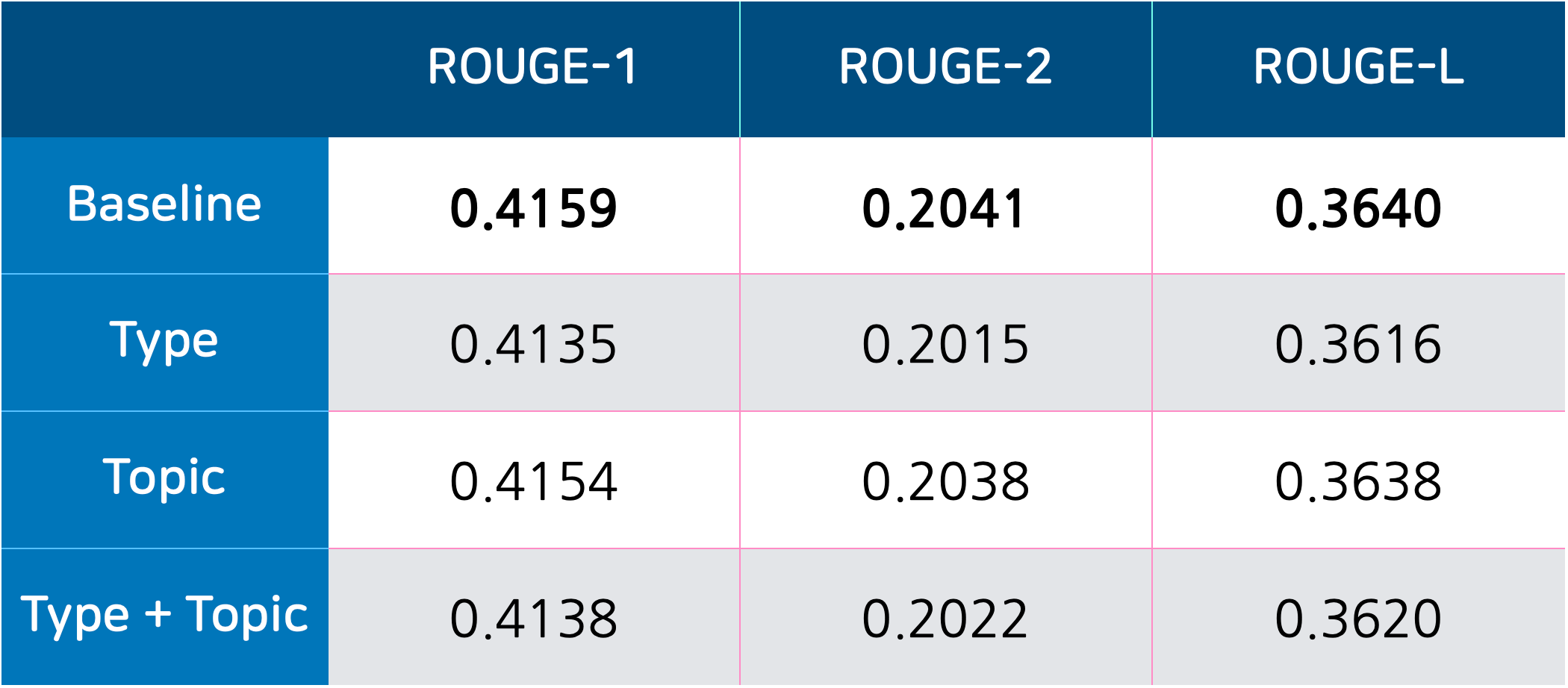
그런데 놀랍게도 결과는 아무것도 사용하지 않은 게 가장 좋았습니다. 하지만 이 사실을 바로 받아들일 수가 없어서 분석을 해보았습니다.
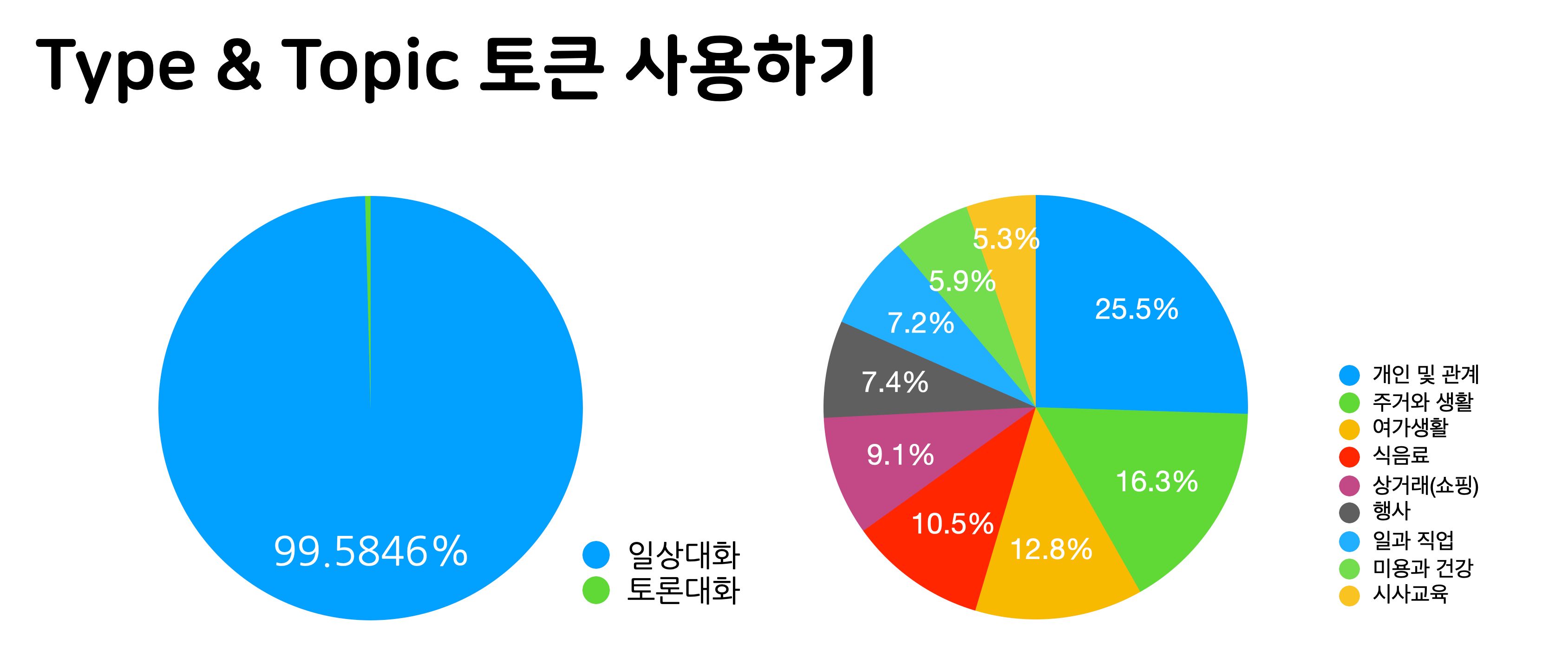
Type 정보가 유용하지 못한 것은 두 Type 간 데이터의 개수가 너무 차이나서 정상적인 학습이 어려웠을 것으로 추정합니다. 토론대화가 극도로 적어서 모델이 학습하는 입장에서는 오히려 noise일 수 있을 것 같습니다.

Topic의 경우는 좀 더 자세히 봤을 때 전체 데이터에서도 기대했던 만큼의 일관성을 보이지 않았을 것으로 추정합니다. 위 예시를 보면 먹는 얘기는 대부분 식음료로 분류되어 있는데 라볶이를 만들어 먹는 게 개인 및 관계로 분류되어 있다거나 하는 경우입니다. 이런 점이 노이즈로 작용했을 것으로 추정합니다.
데이터 전처리

개인정보 비식별 조치 등을 제외하면 데이터가 따로 아무 처리가 이뤄지지 않았는데 전처리하면 성능이 오르지 않을까?
전처리 기준
- 한글 자음, 모음, 큰 의미가 없을 거라고 예상되는 특수기호들은 모두 없앰
- 이모티콘 없앰
- 물음표 마크가 여러 개 중복되어 나올 경우 하나만 살림
- 위 과정으로 인해 문장의 시작이 [SEP]일 경우 없앰
- 위 과정으로 인해 문장의 끝이 [SEP]일 경우 없앰
- 위 과정으로 인해 공백이 여러 개 연속되어 나올 경우 하나로 줄임
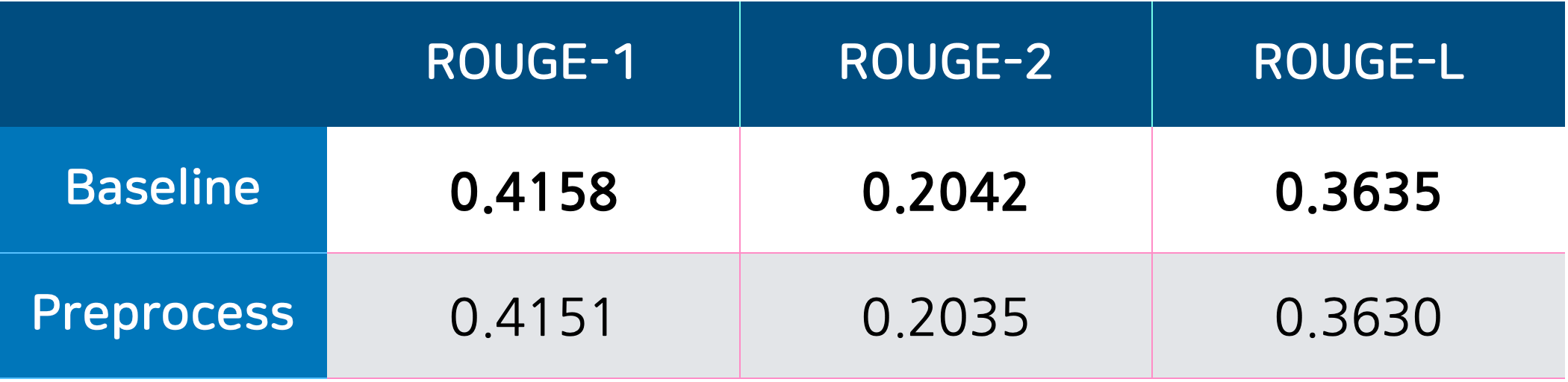
하지만 저렇게 처리했을 때나 추가적으로 좀 더 처리를 실험해봐도 성능이 나아지는 경우가 없어서 이후 실험에서는 데이터 전처리를 고려하지 않았습니다.
Regularization
R-Drop
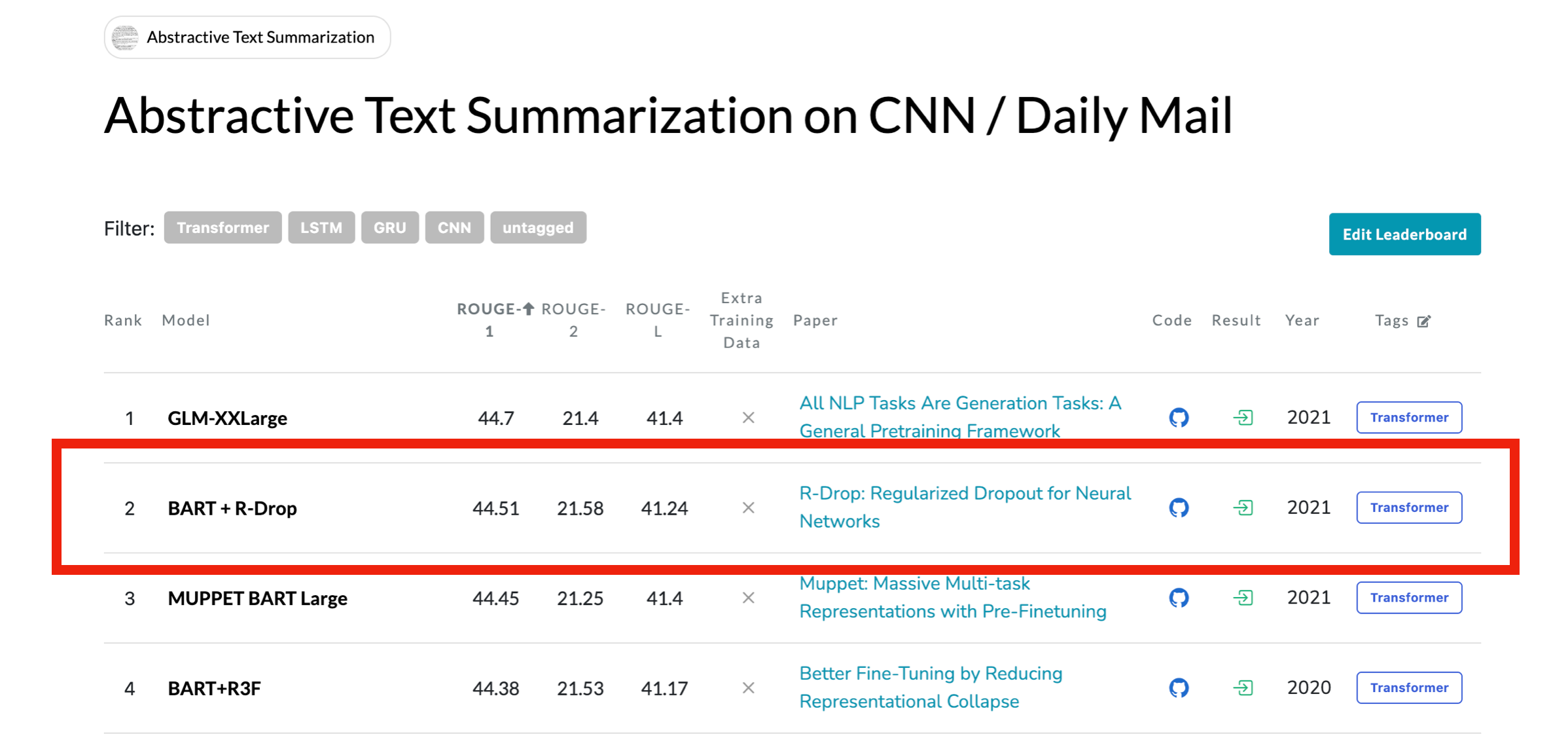
저희는 그냥 저희들의 아이디어를 실험하는 것만이 아니라 현재 요약 Task SOTA 기법들도 계속 리서치를 하면서 진행했습니다. 그러다 저는 CNN/Daily Mail 데이터셋의 리더보드를 확인하다가, R-Drop이라는 방법론을 알게되었습니다.
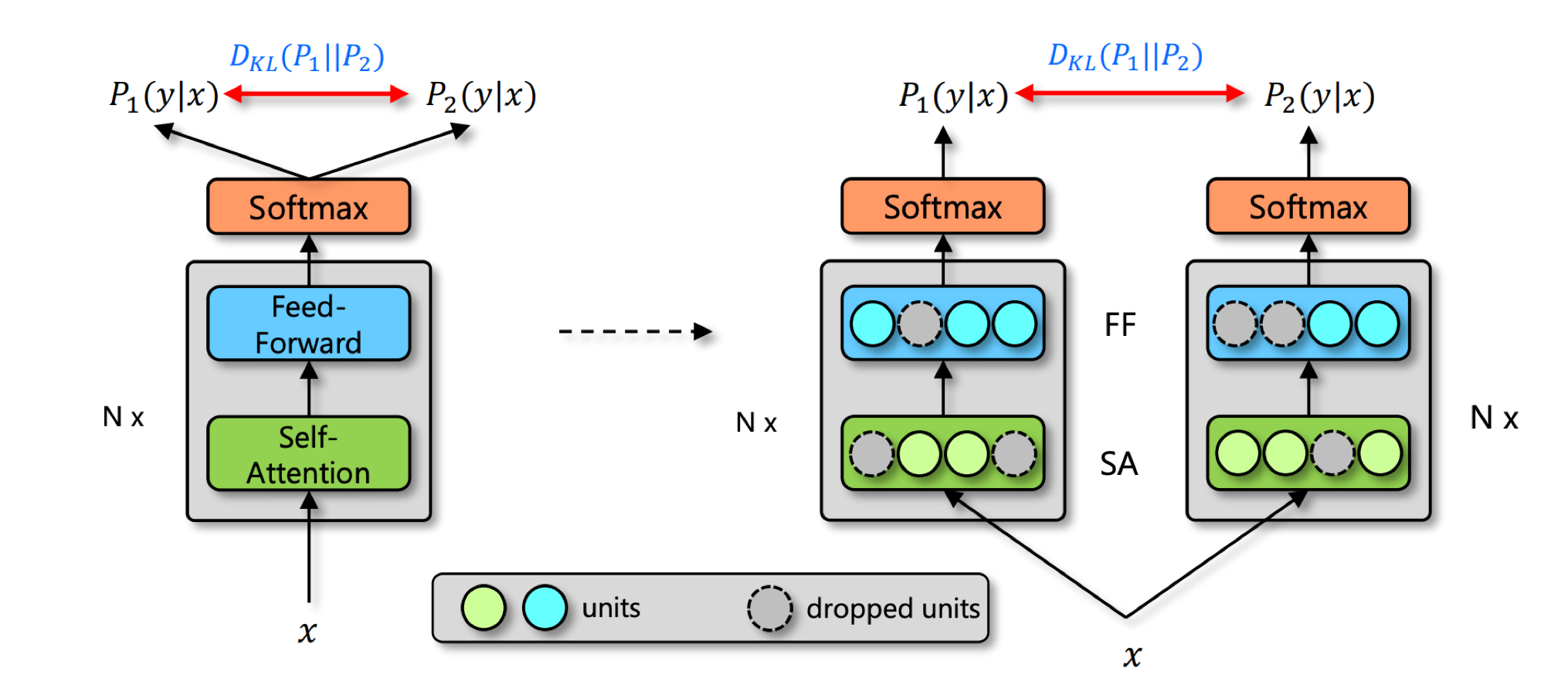
R-Drop 기법을 요약하면 아주 단순한데, 같은 데이터로 모델 추론을 두 번 하면 모델의 Dropout 상태가 달라지기 때문에 두 결과에 차이가 있습니다. 이 두 결과값의 KL Divergence를 loss에 더해주면 됩니다.
저자들은 Dropout 적용의 유무로 학습에서는 모델 일부를 사용하지만 추론 시에는 전부를 사용하며 일관성이 깨지는데 R-Drop은 그 불일치를 줄여주는 효과가 있다고 주장합니다.
또한 이 기법은 요약 말고도 각종 Downstream Task에서 좋은 효과를 보였다고 합니다.

저희도 해봤을 때 적용이 쉽고 단순함에도 유의미한 성능향상을 보였습니다. 하지만 일반적인 사전학습 때처럼 효과가 좋지는 않았죠.
R3F
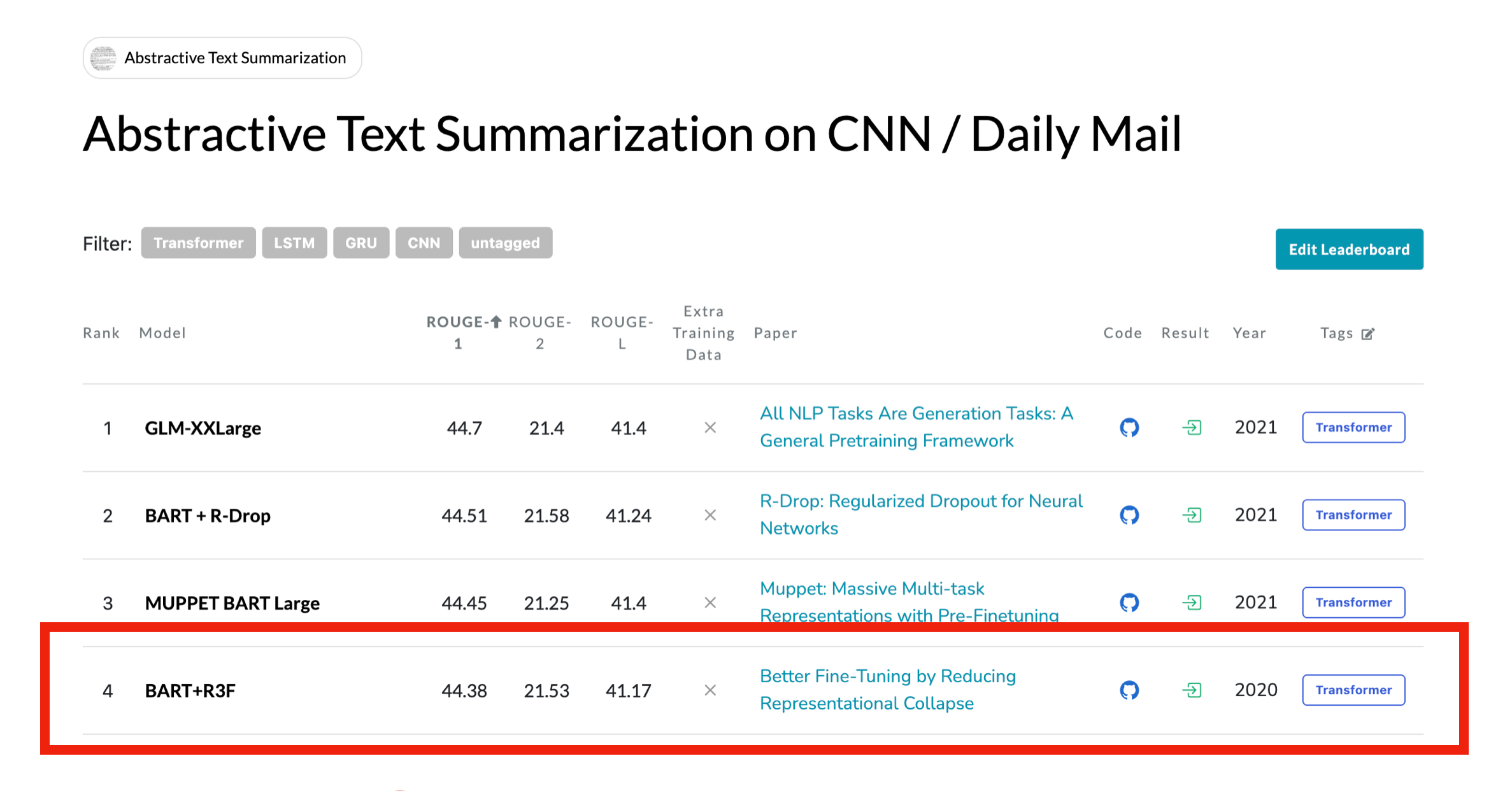
최기원님은 같은 벤치마크의 R3F 논문을 택해 읽기 시작했습니다.
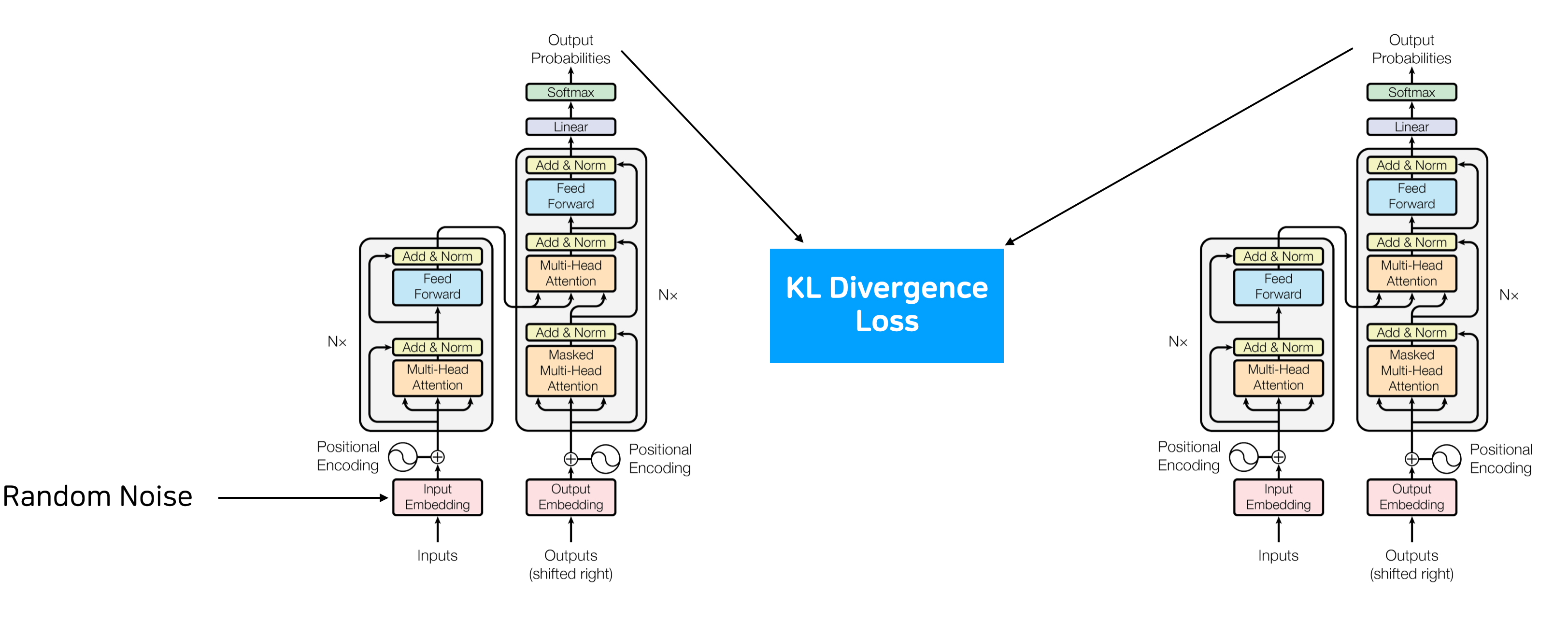
R3F도 regularization 기법인데 여기는 입력에 일부러 random noise를 더해서 추론시키고 평범하게 추론했을 때와의 KL Divergence를 loss로 함께 사용합니다.

R-Drop과 비슷한 정도의 구현 난이도에도 불구하고 높은 성능 향상을 보였으며, R-Drop과 R3F를 함께 사용하기는 어려워 Regularization 기법은 R3F를 사용하기로 했습니다.
Reinforcement Learning

대회 평가 기준은 ROUGE고 학습 loss는 NLL을 쓰는데 평가 메트릭을 직접적으로 학습에 반영할 수 없을까? 근데 ROUGE는 문장을 만들고 다시 형태소 분석기로 잘라서 구하니까 미분이 불가능한데? 그래도 강화학습 기반의 방법론을 적용해볼 수 있지 않나?
라고 생각하고 리서치를 해본 결과 A Deep Reinforced Model for Abstractive Summarization라는 관련 논문을 찾을 수 있었습니다. (대회 당시 기준) 무려 4년전… 무려 Transformer도 나오기 전 논문이었습니다.
A Deep Reinforced Model for Abstractive Summarization
논문의 핵심 아이디어는 다음과 같습니다.
Supervised Teacher Forcing: \(L_{ml} = -\sum_{t=1}^{n'}\log{p(y_t^*|y_1^*, ..., y_{t-1}^*, x)}\)
보통 학습할 때 이렇게 Loss를 계산하지만 이렇게 학습했을 때 ROUGE 같은 discrete한 metric에도 좋다고 보장할 수 없다.
이를 보완하기 위한 방법으로 discrete metric을 maximize 하는 policy를 학습하도록 할 수 있다.
Policy Learning: \(L_{rl} = (r(\hat{y})-r(y^s))\sum_{t=1}^{n'}\log{p(y_t^s|y_1^s,...,y_{t-1}^s,x)}\)
- $y^s$는 매 decoding step마다 $p(y_t^s|y_1^s,…,y_{t-1}^s,x)$ 확률분포에서 샘플링해서 얻은 sequence 출력
- $\hat{y}$은 greedy search로 얻은 baseline 출력
- $r(y)$는 sequence $y$에 대한 보상함수
➜ $L_{rl}$을 최소화하는 것은 $y^s$가 $\hat{y}$보다 높은 보상을 얻었을 때, conditional likelihood를 높여 모델이 더 높은 보상을 얻도록 한다.

특이하게 RL을 적용하면 일관되게 Precision이 오르고 Recall이 떨어졌습니다. 이유를 상세히 분석하지는 못했지만 얕게 추측해봤을 때, 논문에서 소개한 RL 방식은 모델이 정답 문장을 직접 보면서 학습할 수가 없고 sampling으로 탐색을 하며 더 많은 보상(ROUGE-L F1)을 주는 행동을 강화시키며 학습합니다. 그리고 F1 Score가 오르려면 Recall이나 Precision을 올려야 합니다. Recall을 올리려면 정답 문장에 포함된 단어들을 찾아서 추가해야 하고 Precision을 올리려면 불필요한 말을 줄이면 되죠. 그런데 지금 있는 10개의 단어 중에 필요없는 단어를 빼는 게 지금 있는 10개의 단어 사이에 실제 정답에 들어가 있지만 놓친 단어를 8000개의 단어풀 중에 골라서 넣는 것보다 더 탐색해서 얻어걸리기가 쉬워서 그렇게 되지 않을까 생각합니다. (물론 저희는 실제로는 단어가 아니고 형태소입니다.)
결과는 다른 ROUGE의 F1점수는 떨어졌지만 Reward 함수로 사용했던 ROUGE-L F1은 올라서 성공이었습니다.
Ranker
원래 이런 대회는 앙상블로 마무리 해줘야 하는데? 생성모델이니까 그냥 voting처럼은 못하네 그러면 랭커를 만들어서 여러 모델로 만든 요약문 중에 좋은 걸 고르면 어떨까?
근데 모델 여러 개로 추론하기에는 1시간 시간제한 빠듯할 수도? 빔 서치 후보군 중에 Ranker로 골라보는 건 할 만 할듯?
이런 게 있는데? SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization
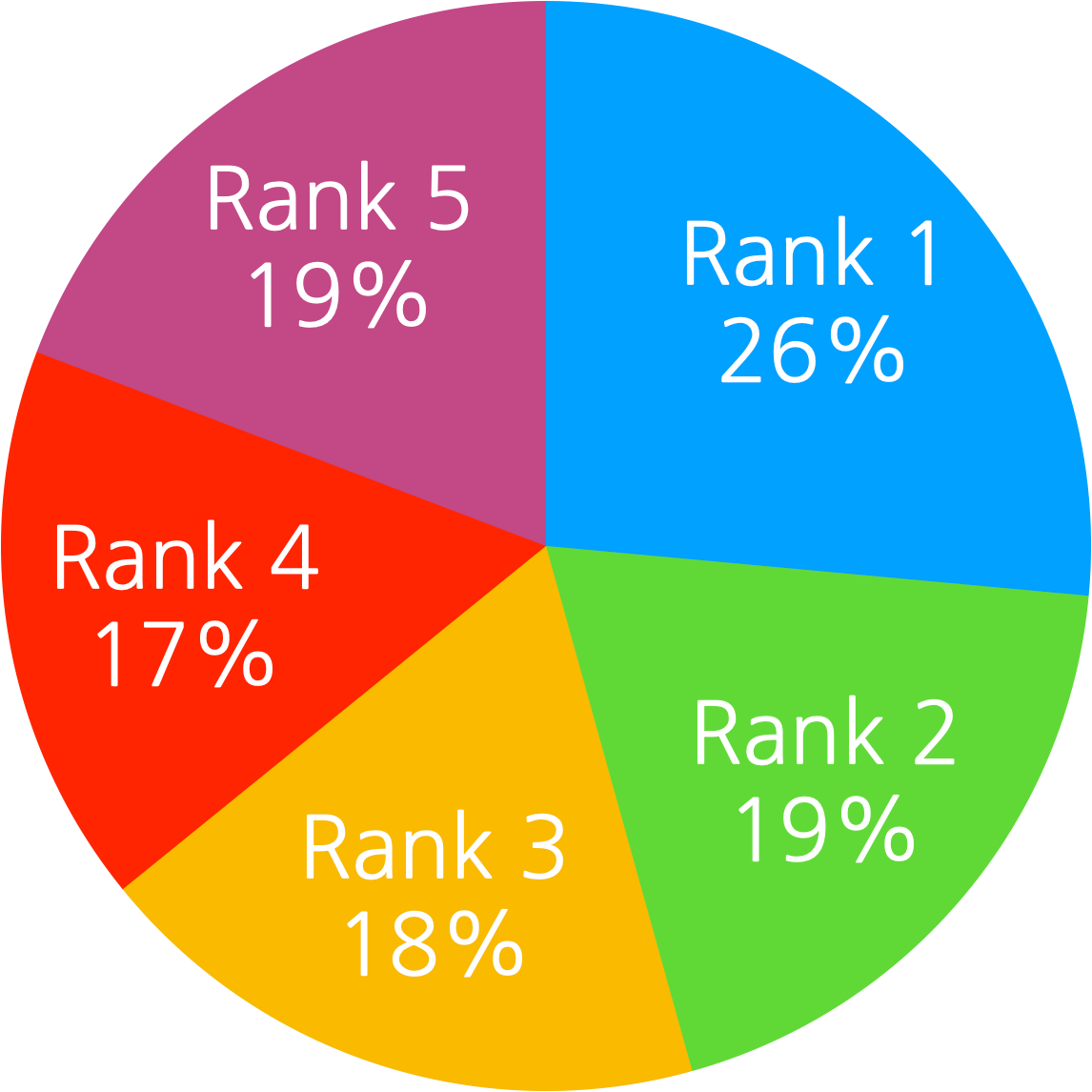
Ranker 개발을 시작하기 전에 생성모델만 사용했을 때 우리가 최종 요약문으로 사용하는 Beam Search Top 1문장이 실제 ROUGE Metric으로는 몇 등인지를 미리 확인했습니다.
만약에 이미 Beam Top 1이 대부분 ROUGE 기준 Top 1이라면 Ranker의 도입효과가 미미할 것으로 판단했으나 실제로는 꽤나 고르게 분포되어 있었습니다.
또한 Ranker가 Beam 내에서 항상 ROUGE-L Top 1를 고른다고 가정하고 ROUGE-L이 최대 어디까지 오를 수 있나 체크해봤을 때 성능 상승의 여지가 많아서 적용해보기로 했습니다.
SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization
논문의 방법론을 간단히 요약하면 다음과 같습니다.
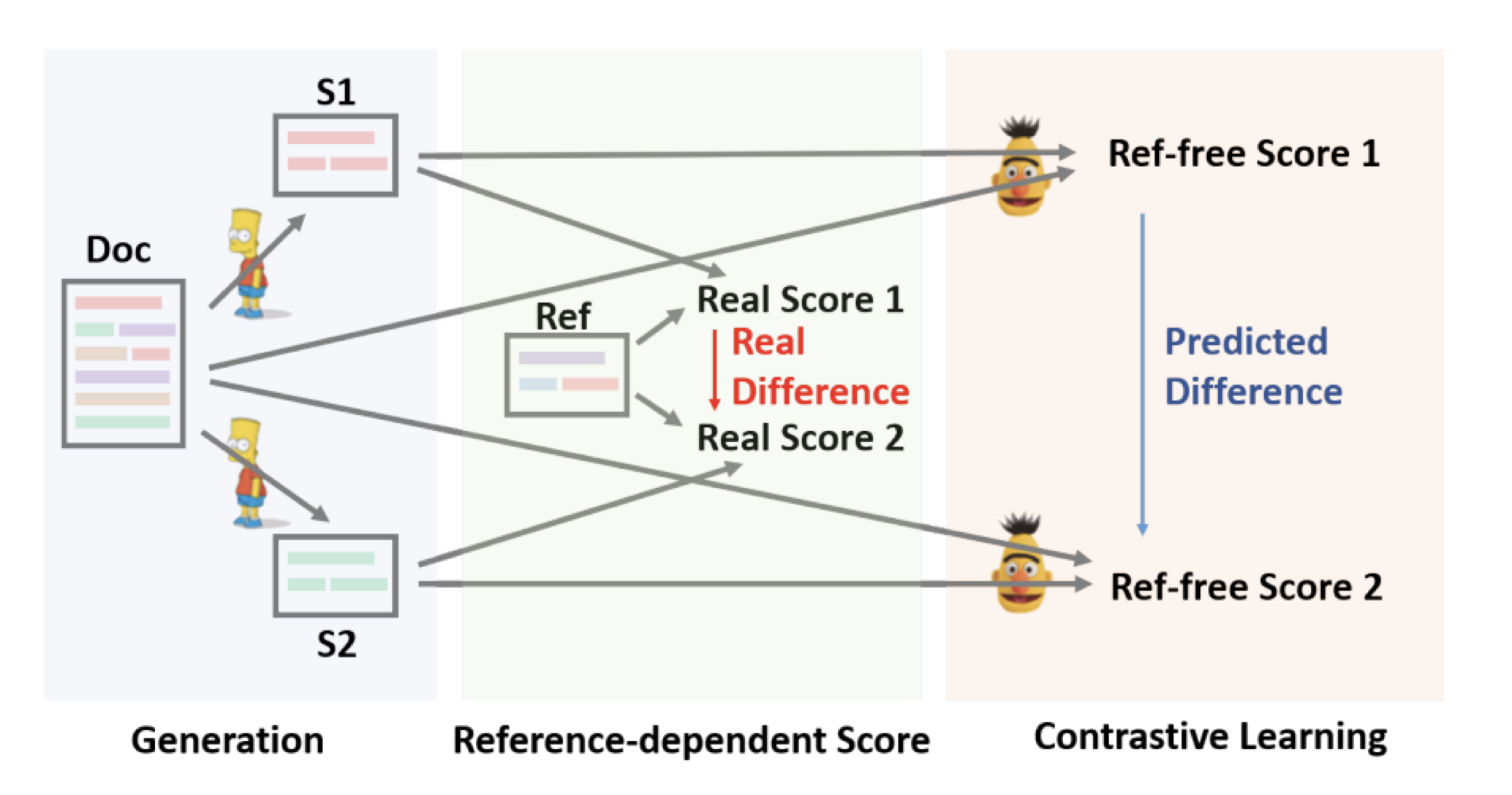
- 후보가 될 요약문 여러 개를 생성하고, 그 요약문들을 Reference 요약문을 이용해 순위를 매김
- 그 순위를 이용해서 Ranking loss로 Contrastive Learning을 진행
- 최종 학습은 Ref-free 점수만 이용하기 때문에 지도학습만으로 Ref정보를 반영해 학습하는 게 가능
$D$: 원본 문서
$\hat{S}$: Reference 요약
$f$: Abstractive 요약 모델
$M$: 평가 metric
모델의 목표는 $m = M(S, \hat{S})$이 가장 높은 후보 요약문 $S = f(D)$를 생성하는 것.
$g$: 생성모델
$h$: 점수를 매기는 모델
Stage 1: Candidates Generation
학습된 생성모델 $g$는 빔서치 등의 디코딩 전략을 사용해 여러 개의 후보 요약문($S_1, …, S_n$) 을 생성합니다.
Stage 2: Reference-free Evaluation
기본적인 아이디어는 더 좋은 요약문 $S_i$가 그렇지 못한 요약문보다 높은 점수를 얻어야한다는 것
모델 $h$의 목표는 문서와 후보 요약문 만으로 점수 $r_i = h(S_i, D)$를 구하는 것
최종 요약문은 $S = \mathbf{argmax}_{S_i} h(S_i, D)$
모델은 $S_i$와 $D$를 각각 encoding하고 cosine 유사도를 점수 $r_i$로 사용
\[L = \sum_i \max(0,h(D,\tilde{S}_i) - h(D,\hat{S})) + \sum_i \sum_{j>i} \max(0, h(D, \tilde{S_j})-h(D, \tilde{S}_i)+ \lambda_{ij})\]여기서 $\tilde{S_1}, …, \tilde{S_n}$은 $M(\tilde{S_i}, \hat{S})$ 기준 내림차순으로 정렬
$\lambda_{ij} = (j-i)*\lambda$ 이며, $\lambda$는 하이퍼파라미터
식에서 앞부분은 모든 모델 생성 요약문보다 Reference가 점수가 높도록 학습시키는 loss이고,
뒷부분은 실제 랭킹이 더 높은 생성 요약문이 낮은 요약문보다 점수가 더 높도록 학습시키는 loss

이 기법을 적용했을 때 놀랍게도 지금까지 올랐던 각종 방법론들 다 합친 것보다 많이 올랐지만 대회에 nsml로 제출한 점수는 기존보다 오히려 약간 떨어졌습니다.
대회에서 ROUGE-L 계산에 사용하는 형태소 분석기는 공개되지 않았는데 저희가 사용한 형태소 분석기가 대회에서 사용한 것과 달라 너무 우리 메트릭에 overfitting된 게 아닐까 정도만 추측하였습니다. 결국 Ranker는 경진대회에서는 도움이 되지는 못했습니다.
그런데 나중에 저희가 ROUGE를 계산하기 위해 사용하고 있던 라이브러리가 특정한 경우에는 올바르지 않은 값을 내는 것을 알게 되었습니다. 어쩌면 이것 때문에 메트릭 계산이 정교하지 못해서 제대로 학습이 안되었을 수도 있겠다 싶지만 어쩔 수 없네요. ㅠㅠ
결과
방법론 요약
결과적으로 저희가 본선 1등을 위해서 사용한 방법을 요약하면 아래와 같습니다.
개인적으론 Ranker를 적용하지 못한 것이 가장 아쉽습니다.
1. BART pretraining
모델 아키텍쳐로는 BART를 사용했습니다. 외부 데이터를 사용할 수 없기 때문에 학습 데이터셋의 대화 텍스트로 사전학습을 수행했으며 노이즈는 Token Masking과 Sentence Permutation을 적용했습니다. Sentence Permutation은 턴 단위로 수행하였습니다.
2. Dialogue Summarization finetune (R3F)
사전학습 후에는 Dialogue Summarization task를 학습시켰습니다. 이때 Abstract Summarization에서 좋은 효과를 보이는 R3F 기법을 적용하였습니다.
3. Dialogue Summarization finetune (RL)
마지막으로 학습의 목표를 대회의 평가지표인 ROUGE-L F1 점수와 align시키기 위해서 고전적인 RL을 적용했습니다. target metric은 모델이 생성한 요약문과 실제 요약문간의 mecab 분절 기준 ROUGE-L F1 score를 사용하였습니다.
추가자료
대회에서 사용했던 방법론을 공유하기 위해 Public 레포지토리를 만들어두었습니다.
cosmoquester/2021-dialogue-summary-competition에서 확인하실 수 있습니다.
레포의 README를 읽어보시면 저희가 학습시킨 모델을 써볼 수도 있고 학습 추이를 살펴보거나 직접 학습 코드를 돌려볼 수 있습니다.
References
- 관점의 탄생과 진리의 종말
- A Survey on Dialogue Summarization: Recent Advances and New Frontiers
- An Empirical Study of Tokenization Strategies for Various Korean NLP Tasks
- Attention Is All You Need
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- Pre-Training a Language Model Without Human Language
- Does Pretraining for Summarization Require Knowledge Transfer?
- R-Drop: Regularized Dropout for Neural Networks
- Better Fine-Tuning by Reducing Representational Collapse
- A Deep Reinforced Model for Abstractive Summarization
- SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization