AWS Inferentia 를 이용한 모델 서빙 비용 최적화: 모델 서버 비용 2배 줄이기 1탄
AWS 고객감사 특별 할인... 모델 서빙 비용 최대 80% 초특가 할인전


머신러닝 엔지니어링(MLE)팀에서는 제품에 사용되는 여러 딥러닝 모델을 최대한 낮은 지연 시간과 적은 비용으로 서빙하기 위해서 여러 하드웨어 및 소프트웨어 최적화 기법을 실험해보고 실제 프로덕트에 적용하고 있습니다. 높은 수준으로 최적화된 모델 서빙은 실제 서비스에서 더 큰 모델을 사용할 수 있는 추론 시간(Latency)와 예산을 확보해 줄 수 있기 때문에, MLE 팀에서는 모델 서빙 최적화를 모델 학습만큼이나 중요한 아젠다로 다루고 있습니다.
본 포스트에서는 저희 팀이 현재 실시간 모델 추론에 사용하고 있는 딥러닝 추론 가속 하드웨어인 AWS Inferentia에 대해서 소개하고, Inferentia를 이용해서 기존 GPU 대비 2배 이상 서빙 비용을 절약한 노하우를 공유해 드리려고 해요.
AWS Inferentia 란? 🤔

AWS Inferentia Chip 은 AWS re:Invent 2019 Keynote에서 최초로 공개되었는데요. 당시에 유튜브로 re:Invent를 지켜보다가 “AWS가 이제 ML 전용 칩까지 만든다고?” 하면서 놀랐던 기억이 생생합니다.
AWS Inferentia는 딥러닝 모델 추론 가속화에 초점을 맞추어 설계된 Amazon 최초의 자체 개발 칩입니다. Inferentia는 FP16&BF16 기준 64 teraFLOPs / INT8 기준 128 teraFLOPs 를 처리할 수 있으며 작은 배치 크기로 처리량을 극대화하도록 최적화되어 있습니다. Tensorflow, PyTorch, MXNet을 기반으로 학습된 모델을 쉽게 Inferentia에서 추론 가능한 그래프로 변환하여 사용할 수 있고, AWS EKS(Elastic Kubernetes Service)에서도 사용 가능하기 때문에 Production 환경에서 손쉽게 사용할 수 있도록 개발되었습니다.
그중에서도 저희의 이목을 끈 문장은 AWS Inferentia 공식 문서에 나와 있는 “T4 GPU 기반 인스턴스(g4dn.*)에 비해 추론당 최대 40% 저렴한 비용으로 최대 2.3배 더 많은 처리량을 처리할 수 있다” 라는 문장이었습니다. 저희도 기존에는 AWS 의 g4dn instance를 이용해서 모델 서빙을 하고 있었기에 Inferentia가 하드웨어 레벨에서 비용을 빠르게 최적화할 수 있는 방법이 될 수도 있겠다는 판단을 하였습니다. 하지만 실제로 해보기 전까지는 확신할 수 없는 법! 꼼꼼하게 실험 계획을 세워서 Inferentia가 GPU를 대체할 수 있을지 검증해 보기로 하였습니다.
루다의 ML 모델 서빙 👩🏻💻
먼저 저희가 서빙해야 하는 모델을 간략하게 소개해 드리겠습니다. 현재 저희는 RoBERTa-Base와 동일한 크기/아키텍쳐의 모델을 자체적으로 사전학습 및 Fine-Tuning하여 사용하고 있습니다. 구체적으로 Fine-Tuning에 사용되는 테스크를 소개해 드릴 수는 없지만 기존에 공개되었던 자료 를 통해서 간략한 힌트를 얻으실 수 있을 것 같습니다. 간단하게는 RoBERTa-Base 모델을 추론하는 것과 동일한 연산량을 요구한다고 생각하시면 될 것 같습니다.
학습된 모델은 Tensorflow, PyTorch 두 프레임워크에서 모두 사용할 수 있도록 사내 라이브러리가 구축되어 있기 때문에 리서치팀 그리고 서빙을 담당하는 팀에서 각자 자유롭게 원하는 프레임워크를 사용할 수 있습니다. 본 최적화에서는 Tensorflow 를 이용하기로 하였습니다. Tensorflow 를 사용하면 Tensorflow Serving 을 이용해서 손쉽게 Model API 를 배포할 수 있다는 장점이 있기 때문입니다. 물론 PyTorch 모델을 FastAPI 와 같은 Python Web Framework 를 이용해서 서빙하는 방법도 있지만 TF Serving 에서 제공해주는 Dynamic Batching, Remote Storage Access 등 기본으로 제공해 주는 기능이 많기 때문에 핑퐁팀에서는 Tensorflow Serving을 사용하고 있습니다.
Tensorflow 모델 Neuron Compile 하기 ✈️
Inferentia 하드웨어를 이용해 모델을 추론하기 위해서는 그래프를 컴파일하는 과정이 필요합니다. 컴파일 과정에서는 모델의 추론 과정을 Tracing 하고 고정된 추론 그래프 형식으로 만들게 됩니다. 고정된 추론 그래프의 특성상 Python 로직이 복잡하게 포함되어 있는 모델 코드나 입력에 따라서 추론 Flow 가 동적으로 달라지는 모델은 Inferentia에서 추론할 수 없습니다. 또한 Batch 크기를 제외하고, 입출력 시 Tensor의 shape이 dynamic 하게 달라질 수도 없습니다. 위와 같은 제약조건에 부합하지 않는다면 Inferentia에서 추론하는 것은 적합하지 않습니다. 입출력의 크기가 달라지는 경우, 입/출력에 Padding을 통해서 항상 고정된 크기의 입력 Tensor 를 보장해 주는 것도 한 가지 방법입니다.
AWS에서는 그래프를 쉽게 컴파일할 수 있도록 Neuron SDK를 제공하고 있습니다. Neuron SDK의 Tensorflow, PyTorch API를 사용하여 모델을 Neuron Compile 하고 이를 inf1 EC2에서 배포할 수 있어요. 이번 챕터에서는 Neuron SDK 를 사용하여 Tensorflow 2.x로 학습된 Model을 Compile 하는 방법을 소개해볼게요.
Step1. Inferentia Instance 세팅하기 🤖
Inferentia에서 추론 가능한 그래프는 Inferentia가 포함되지 않은 일반 인스턴스에서도 컴파일할 수 있습니다. 컴파일 시 많은 양의 Host Memory를 요구하기 때문에 저희도 주로 inf1.* 계열 인스턴스를 사용하지 않고, c5.* 계열의 인스턴스를 이용해 컴파일을 진행하였습니다. 또는 inf1.6xlarge(48GiB), inf1.24xlarge(192GiB) 와 같은 Host Memory 크기가 충분한 Inferentia 인스턴스를 이용해서 컴파일하는 것도 방법이 될 것 같습니다. (RoBERTa-Large를 Compile 할 땐 약 200GB 이상의 Memory가 필요했습니다)
실제 Inferentia를 이용해서 추론 서비스를 운영할 때에는 Inferentia 전용 인스턴스 ( inf1.* ) 를 사용해야 합니다. Amazon 페이지에서 EC2 Inf1 인스턴스 유형 및 요금 등을 소개하고 있으니 팀의 니즈에 따라 인스턴스를 고를 수 있습니다. AWS 서울 리전(ap-northeast-2)에서도 사용할 수 있으니 실제로 서비스할 때에도 도움이 많이 되겠죠?
인스턴스를 생성할 때에 AWS Deep Learning AMI 를 사용하면 Neuron SDK 를 바로 사용할 수 있어요. AMI 내에는 Neuron Core (Inferentia)에 대한 Driver와 Tensorflow, PyTorch, Conda 등이 미리 설치되어 있습니다. 하지만 Neuron SDK 에서 지원하는 최신 Tensorflow, Pytorch 등은 설치되어 있지 않기 때문에 별도의 셋업 과정이 필요합니다. 또한 Deep Learning AMI를 사용하지 않고 Neuron SDK를 설치해야 하는 경우도 별도의 설치 과정이 필요로 합니다. Neuron SDK 설치 및 호환되는 Tensorflow / Pytorch 설치 방법은 다음 문서를 참조해 주세요!
Step2. Neuron Compile 하기 🔥
Inferentia 로 컴파일할 준비가 모두 완료되었다면 이제 실제 모델을 Compile해 보도록 하겠습니다. 예시로서 사전 학습된 klue/roberta-base 모델을 불러오고, 입력에 대한 Pooled Output과 Encoder Output을 반환하는 그래프를 컴파일해보려고 합니다. 다음 코드를 Python으로 실행하면 됩니다.
from transformers import TFRobertaModel
import tensorflow as tf
import tensorflow.neuron as tfn
# 사전학습된 RoBERTa 모델 불러오기
model = TFRobertaModel.from_pretrained('klue/roberta-base', from_pt=True)
# 모델의 예시 입력 (shape 만 동일하면 되고, 랜덤한 값을 넣어주면 됩니다)
dummy_input_ids = tf.random.uniform([1, 128], maxval=10000, dtype=tf.int32)
dummy_attention_mask = tf.ones([1, 128], maxval=10000, dtype=tf.float32)
# Trace 를 통해서 추론 그래프를 생성합니다.
model_neuron = tfn.trace(model, [dummy_input_ids, dummy_attention_mask])
# Neuron Compiled 된 model_neuron 를 저장합니다.
tf.saved_model.save(model_neuron, './roberta-base-neuron/1')
tfn.trace 함수는 keras.Model이나 tf.function으로 데코레이팅된 Python Callable 객체를 입력으로 받아 Inferentia에서 추론 가능한 그래프로 변환해줍니다. 컴파일이 완료되면 trace 된 그래프가 반환되고, SavedModel API를 통해 그래프를 SavedModel 형식으로 저장할 수 있습니다.
더욱 자세한 설명은 AWS Neuron Documentation 을 참고해주세요.
Step3. Neuron Trace 된 모델 추론해보기 ⚡️
위 환경들을 모두 셋업 한 후, SavedModel 형식으로 저장된 모델을 Inferentia Instance 위에서 불러오면 별도의 device를 지정하지 않아도 Neuron Device 위에 해당 모델이 로딩됩니다. 기존 Tensorflow 코드로 추론을 하는 것과 동일하게 모델을 선언한 뒤에 입력으로 사용할 Tensor를 인자로 넘겨주면 모델 추론 결과가 반환되게 됩니다. 최초 1-5회 정도 추론의 경우에는 warmup으로 인해서 추론 시간이 다소 느리게 진행되는 점 알고 계시면 좋을 것 같아요.
import tensorflow as tf
model = tf.saved_model.load("./roberta-base-neuron/1")
@tf.function
def inference(input_ids, attention_mask):
return model([input_ids, attention_mask])
BATCH_SIZE, SEQ_LEN = 1, 256
input_ids = tf.random.uniform((BATCH_SIZE, SEQ_LEN), maxval=1000, dtype=tf.int32)
attention_mask = tf.ones((BATCH_SIZE, SEQ_LEN), dtype=tf.float32)
pooled_output, encoder_output = inference(input_ids, attention_mask)
# tf.Tensor(1, 512), tf.Tensor(1, 256, 512)
Tensorflow Serving 을 이용해서 추론하는 방법도 있는데요! 이 방법은 다음 블로그 글에서 다루어 보도록 하겠습니다 :) 🙇♂️
GPU와의 속도/비용 비교 💸
그럼 정말 Inferentia가 비용 효율 측면에서 GPU보다 더 좋은지 비교해 보아야겠죠? 저희는 간단한 부하 테스트 스크립트를 작성해서 각 인스턴스 별로 성능 및 비용을 비교해 보았습니다. 부하 테스트 툴을 사용하면 보다 엄밀하게 측정이 가능하겠지만, 여러 변인들을 빠르게 실험하고자 Python으로 부하 테스트 스크립트를 작성하였습니다.
저희는 1개의 추론당 소요되는 평균 Latency를 측정하기 위해서 100번의 추론을 수행하고, 각 추론 별로 소요된 시간의 평균을 측정하는 방식을 사용하였습니다. Throughput을 측정할 수 있는 지표인 RPS(Request Per Second)는 측정된 Latency를 이용해서 1000ms / latency(ms) * batch-size 로 계산하였습니다. 이런 방식으로 Throughput을 계산한 이유는 한 개의 GPU 또는 Neuron device가 동시에 여러 개의 추론을 동시에 수행할 수 없고 들어온 입력을 순차적으로 처리하기 때문에 1초에 계산할 수 있는 총 RPS는 latency 와 완전히 선형 관계이기 때문입니다.
추론 비용은 1000RPS의 요구조건을 가정하고 계산하였습니다. 1000RPS를 각 인스턴스가 처리할 수 있는 RPS로 나누어서 필요한 인스턴스의 개수에 인스턴스 시간당 비용을 곱해 계산하였습니다. 추가적으로 서버 개수에 소수점이 생기는 것을 방지하기 위해서 소수점은 올림을 적용하였습니다.
다만 위와 같은 세팅으로 1000개의 request를 1초 내에 처리할 수 있는 것은 맞지만, 모든 request가 들어오자마자 처리되는 것이 아니기 때문에 실제 서비스 latency는 위에서 계산한 latency에 비해 더 느릴 수 있습니다. 실서비스 성능에 대한 부하 테스트는 이어지는 다음 블로그 글에서 보다 세부적으로 다루어 보도록 하겠습니다!
실험 환경 🛹
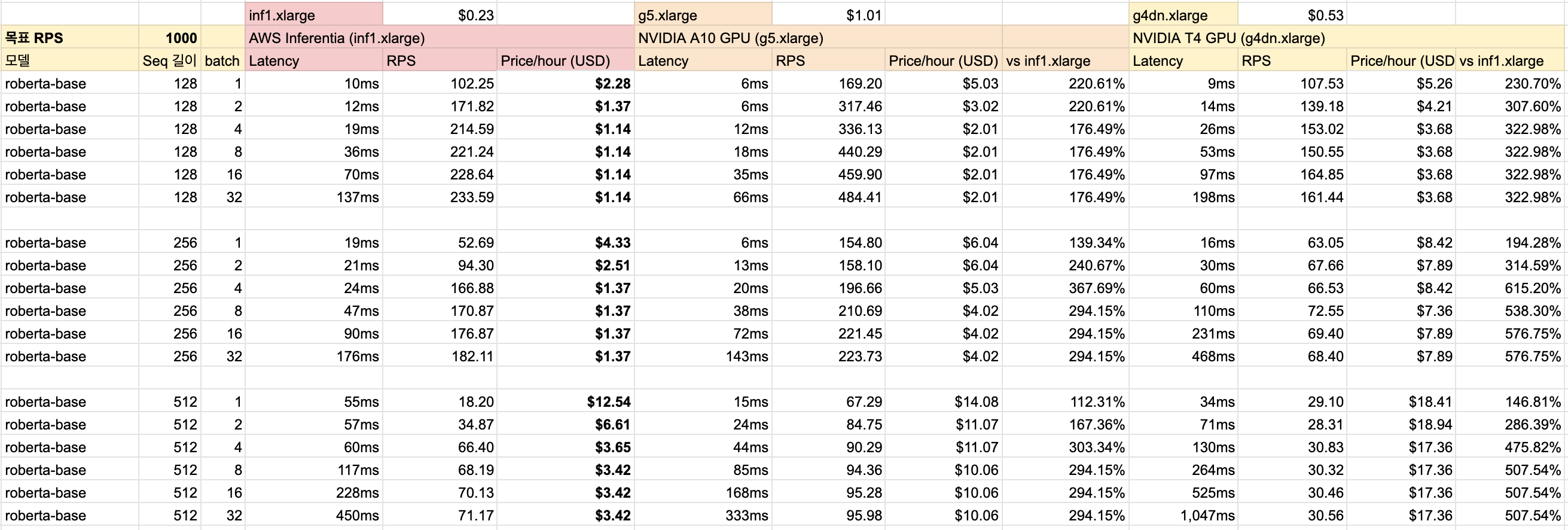
메인으로 Inferentia 인스턴스(inf1.xlarge, $0.23/h)를 사용하였고, 추론 용도로 가장 많이 사용되는 T4 GPU(g4dn.xlarge, $0.53/h)와 최근 추가된 추론 특화 GPU인 A10(g5.xlarge, $1.01/h) 를 대조군으로 설정하였습니다. 모든 실험은 Tensorflow로 진행했으며 Inferentia 의 경우에는 Dynamic Shape 을 지원하지 않아 각 sequence length 별로 모델을 따로 Compile 해 실험을 진행하였습니다.
실험 결과 🥇
아래 표는 각 실험별로 Latency, RPS, Price/Hour(USD)를 기록한 결과입니다. 실험 결과 Inferentia가 타 방법론들에 비해 적게는 1.5배 많게는 5.7배 이상 비용이 덜 드는 것을 확인할 수 있었습니다. 이는 Inferentia 측에서 주장했던 바에 어느 정도 합치되는 결과이며 정말로 Inferentia가 비용 절감에 큰 도움이 된다는 것을 검증하였습니다.
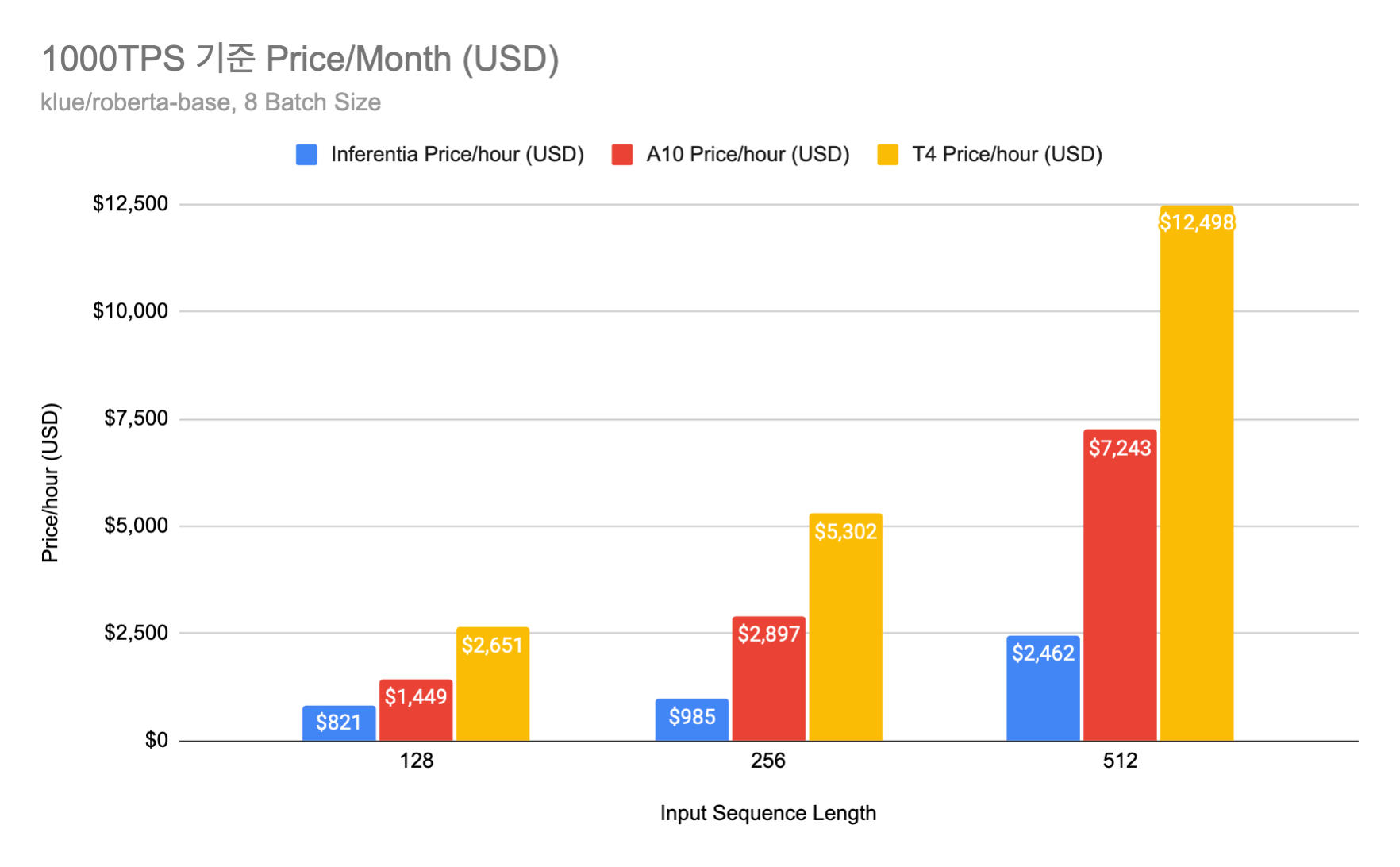
또한 실험 결과 batch size가 8 인 경우에 모든 device의 RPS 가 어느정도 수렴하는 것을 확인하였고, 실제 서비스를 하기에 충분한 수준의 Latency(100ms 전후)를 보여준다고 판단해 이를 기반으로 월별 예상 금액을 추산해 보았습니다. 그 결과 512 입력 길이 기준으로, Inferentia는 약 300만원 / A10 GPU는 약 900만원 / T4 GPU는 1600만원의 비용이 필요한 것을 확인할 수 있었습니다. (1300원/$ 환율 기준) 1000 RPS 의 부하를 견디는 RoBERTa-Base 크기의 모델 서버의 운용 비용이 월에 300만원 정도밖에 안 한다니… 정말 놀라울 따름입니다.
Inferentia 의 한계점 🙅♀️
이렇게 놀라운 가성비에도 불구하고 Inferentia를 사용하지 못하는 경우도 있습니다. 위에서 언급했던 것처럼 고정된 형태의 Graph 를 만들 수 없는 모델 추론은 Inferentia에서 사용할 수 없습니다. 대표적으로 Beam Search와 같은 dynamic graph 사용이 필연적인 Language Generative Model은 Inferentia에서 사용하기 어렵습니다. 또한 Inferentia 하드웨어의 계산 능력이 고성능 GPU(A100, V100, A10) 보다 떨어지다 보니 대형 모델을 추론하는데 Latency가 너무 오래 걸려 서비스에서 사용하지 못하는 경우도 발생할 수 있습니다. 마지막으로 Inferentia에서 지원하는 Graph Ops는 AWS Neuron Docs 에서 확인할 수 있으므로, 컴파일 하고자 하는 모델의 Compatibility가 충분한지 여부도 확인해야 합니다. 이러한 점들을 고려하여 서빙 최적화를 하기 전 Inferentia 도입이 가능할지 여부를 검토해 보시면 좋을 것 같습니다.
마치며 😆
이번 포스트에서는 Inferentia 를 이용해서 모델 서빙 비용을 획기적으로 절약할 수 있는 방법을 알아보았습니다. 실제로 모델을 컴파일해 보고, 실행해보고, 비용과 시간을 계산하여 타 하드웨어에 비해서 좋은 가성비를 갖는다는 것을 알게 되었습니다. 이제 좋다는 것은 알았으니 실제 서비스에 적용해 보는 신나는(?) 일이 남았습니다! 이어지는 다음 블로그 글에서는 Inferentia를 실서비스에서 배포하기 위해 작업한 여러가지 내용(정합성 검증, 전/후처리를 위한 FastAPI 서버, Tensorflow Serving 등)과 모델 서버와 Locust Cluster를 Kubernetes 위에 띄워서 실제 서비스 환경과 동일한 부하 테스트를 진행한 결과를 공유해 드릴게요! 그럼 다음 포스트에서 또 만나요~
Inferentia 외에도 루다에게 들어오는 많은 양의 트래픽을 실시간으로 서빙하기 위한 여러 최적화 방법을 고도화해 나가고 있습니다! 저희와 이런 재미있는 문제를 풀고 싶으시다면 언제든 채용 공고 를 참고해 주세요!