꼼꼼하고 이해하기 쉬운 XLNet 논문 리뷰
Review of XLNet: Generalized Autoregressive Pretraining for Language Understanding



XLNet은 최근에 대부분의 NLP 테스크들에서 state-of-the-art 성능을 달성하고 있던 BERT를 큰 차이로 outperform 하면서 파장을 일으켰습니다. 논문 저자들은 기존의 Language Model들과 BERT의 문제를 지적하면서 새로운 학습 방식과 이 학습 방식을 적용하기 위한 모델을 제안합니다. 이 논문의 핵심 contribution은 다음과 같습니다.
- XLNet은 GPT로 대표되는 auto-regressive(AR) 모델과 BERT로 대표되는 auto-encoder(AE) 모델의 장점만을 합한 generalized AR pretraining model입니다.
- 이를 위해 permutation language modeling objective과 two-stream attention mechanism을 제안합니다.
- 다양한 NLP 테스크에서 기존 대비 상당한 향상을 보이며 state-of-the-art 성능을 보였습니다.
Table of Contents
1. Introduction
최근 많은 양의 corpus를 이용하는 unsupervised representation learning이 활발히 연구되고 있습니다. Pre-training을 통해 얻어진 representation (word2vec, ELMO 등)을 직접적으로 활용하거나 pre-trained model을 downstream task에 대해 fine-tuning 하는 방법(GPT, BERT 등)이 성공적인 결과를 보여주고 있습니다. Pre-training 단계에서도 여러 objective들이 이용되어 왔는데, 그 중 가장 대표적인 두 가지를 소개합니다.
Autoregressive (AR)
일반적인 Language Model (LM)의 학습 방법으로 이전 token들을 보고 다음 token을 예측하는 문제를 풉니다. 대표적으로 ELMO, GPT RNNLM 등이 이에 해당되고 LM의 objective를 수식으로 표현하면 다음과 같습니다.
\[input \space sequence : x = (x_1, x_2, ..., x_T)\] \[forward \space likelihood:p(x) = \Pi^T_{t=1} p(x_t \mid x_{<t})\] \[training \space objective(forward) : \max_{\theta} \space \log p_{\theta}(x) =\max_{\theta} \space \Sigma^T_{t=1} \log p(x_t \mid x_{<t})\]Likelihood & Objective
- 주어진 input sequence의 likelihood는 forward / backward 방향의 conditional probability들의 곱으로 나타냅니다.
- 모델은 이러한 conditional distribution을 objective로 학습합니다.(negative-log likelihood)
AR은 방향성(forward, backward)이 정해져야 하므로, 한쪽 방향의 정보만을 이용할 수 있습니다. 따라서 양방향 문맥을 활용해 문장에 대해 깊이 이해하기 어렵습니다. ELMO의 경우 양방향을 이용하지만, 각각의 방향에 대해 독립적으로 학습된 모델을 이용하므로 얕은 이해만 가능합니다.
Auto Encoding (AE)
Auto Encoder는 주어진 input에 대해 그 input을 그대로 예측하는 문제를 풀고, Denoising Auto Encoder은 noise가 섞인 input을 원래의 input으로 예측하는 문제를 풉니다. BERT같은 경우는주어진 input sequence에 임의로 추가한 noise([MASK] token)가 주어졌을 때,[MASK] token 을 원래 input token으로 복구하고자 합니다. 따라서 Denoising Auto Encoder의 방식으로 볼 수 있습니다.
Likelihood & objective
일반적인 Denoising Autoencoder의 likelihood \(p(\overline{x} \mid \widehat{x})\) 와 이를 Maximize하는 objective를 이용합니다. 하지만 이를 계산하는 과정(위 식의 우변)에서 다음과 같은 차이점이 있습니다.
- Independent assumption: 주어진 input sequence에 대해 각
[MASK]token 의 정답 token이 등장할 확률은 독립이 아니지만, 독립으로 가정합니다. → 독립이므로 각 확률의 곱으로 나타낼 수 있습니다. (objective의 우변) - \(x_t\)가
[MASK]token일 경우, \(m_t = 1\), 나머지 경우에는 \(m_t = 0\) ⇒[MASK]token에 대해서만 prediction을 진행합니다. \(m_t\)를 둬서[MASK]token만 예측하는 objective는 Denoising Autoencoder의 objective(input + noise에 대해 input을 복원, 즉 noise의 위치와 관계없이 input 전체를 복원)와 다르지만 noise를 원래의 input으로 복원하는 개념상 비슷하다고 볼 수 있습니다.
AR과 달리 AE는 특정 [MASK] token을 맞추기 위해 양 방향의 정보를(Bi-Directional Self-Attention) 이용할 수 있다는 장점이 있습니다. 하지만 independant assumption으로 모든 [MASK] token이 독립적으로 예측됨으로써 이들사이의 dependency를 학습할 수 없다는 치명적인 단점이 있습니다. 또한 noise([MASK] token) 자체는 실제 fine-tuning 과정에는 등장하지 않으므로, pre-training 과 fine-tuning 사이의 불일치가 발생합니다.
2. Proposed Method: XLNet
위에서 제안했던 기존 방식들의 장점을 살리고 단점을 극복하기 위해 다음과 같은 흐름으로 새로운 방법을 제안합니다. 각 단계에서 어떤 문제때문에 새로운 방법이 제안되었는지 인과관계를 주의깊게 살펴볼 필요가 있습니다.
- 새로운 Objective (Permutation Language Modeling)
- 이를 반영하기 위한 Target-Aware Representation
- 위 내용들과 Transformer 구조를 동시에 이용하기 위한 새로운 Two-Stream Self-Attention 구조
Permutation Language Modeling Objective
AR과 AE의 장점을 살리고 단점을 극복하기 위한 새로운 Permutation Language Modeling Method를 제안합니다. 이를 수식으로 나타내면 다음과 같습니다.
\[input \space sequence : x = (x_1, x_2, ..., x_T)\] \[likelihood : \mathbb{E}_{z\backsim Z_T}[\Pi_{t=1}^Tp(x_{z_t} \mid x_{z<t})]\] \[training \space objective :\max_{\theta} \space \mathbb{E}_{z\backsim Z_T}[\Sigma_{t=1}^T \log \space p_{\theta}(x_{z_t} \mid x_{z<t})]\]Likelihood & Objective
input sequence index(순서)의 모든 permutation을 고려한 AR 방식을 이용합니다. 예를들어, input sequence \([x_1, x_2, x_3, x_4]\) 에 대해서 index(순서)의 permutation의 집합은 총 \(4! = 24\) 개가 존재하며 \(Z_T = [[1,2,3,4], [1,2,4,3],[1,3,2,4] … [4,3,2,1]]\) 로 나타낼 수 있습니다. 위에서 구한 각 \(Z_T\)에 대해 AR Language Model의 objective를 적용하면 다음 그림과 같습니다. (\(\text{mem}^{(m)}\)은 Transformer-XL의 memory state로 나중에 설명합니다.)
- 각 token들은 원래 순서에 따라 positional encoding이 부여되고, permutation은 token의 index(순서)에 대해서만 진행합니다. 따라서 positioanl encoding에 의해 \(p(x_1\vert x_3,x_2)\) 를 계산할 때 \(x_1\) 은 \(x_2\)보다 상대적으로 앞의 위치에, \(x_3\) 은 \(x_2\) 보다 상대적으로 뒤의 위치에 있다는 것을 구분할 수 있습니다.
- 각 순서들에 대해 \(x_3\) 를 예측하는 부분(초록색)을 보면 \(x_3\) 를 예측하기 위해 \([x_4], [x_2, x_4], [x_1,x_2,x_4]\) 를 이용합니다. 모든 permutation(\(Z_{T}\))에 대해 위 과정을 수행하면 \(x_3\)를 제외한 \([x_1,x_2,x_4]\) 의 모든 부분집합에 conditional한 \(x_3\) 의 probability를 계산할 수 있습니다. 그러므로 특정 token에 대해 양방향 context를 고려한 AR Modeling이 가능해지고 기존 AR방식의 한계를 극복할 수 있습니다.
- AR 방식이므로 independent assumption을 할 필요가 없고,
[MASK]token을 이용하지 않으므로, pre-training과 fine-tuning사이의 불일치도 없고 AE방식의 한계를 극복할 수 있습니다.
Target-Aware Representation for Transformer
Permutation LM Objective를 이용하면 이론상 기존의 AR과 AE방식의 한계를 극복할 수 있습니다. Transformer 구조를 이용한 모델들 (BERT, GPT 등)은 그 압도적인 능력을 다양한 downstream task (SQuAD 등)에서 증명했습니다. 이 구조에서 위 objective를 구현하기 위해서 새로운 representation을 제안합니다.
Masking Strategy
AR LM의 objective는 이전 token들을 보고 다음 token을 예측하는 것입니다. 따라서 학습시에는 conditional한 token들만 보고 나머지 token들은 masking하여 다음 token을 예측하도록 구성했습니다. 예를 들어, \(p(x) = p(x_2) p(x_3 \mid x_2) p(x_1 \mid x_2, x_4) …\)에서 \(x_3\)를 예측할 때는 \(x_2\)를 제외한 모든 input을 masking, \(x_1\)을 예측할 때는 \(x_2, x_4\)을 제외한 모든 input을 masking하는 방식으로 likelihood를 계산합니다.
Problems
제안한 objective의 likelihood부분에 Softmax function을 적용하면 다음과 같습니다.
\[p_{\theta}(x_{z_t} \mid x_{z<t}) =\frac{exp(e(x)^Th_{\theta}(x_{z<t})}{\Sigma_{x'}exp(e(x')^Th_{\theta}(x_{z<t}))}\]위 식에서 나타나는 transformer의 hidden representation \(h_{\theta}(x_{z<t})\) 는 \(x_{z<t}\) 즉, 현재 target index 이전의 context token들에만 의존합니다. 하지만 이렇게 계산한 결과는 현재 예측하고자 하는 target index의 position에 관계없이 같은 값을 갖게되는 문제가 발생합니다. 전통적인 AR objective에서는 input sequence를 정해진 방향(forward, backward)로 넣어주기 때문에 다음에 예측할 target index의 position이 명확합니다. 그러나 제안한 objective는 index를 permutation한 후 진행하기 때문에 이전까지의 index가 같더라도 여러 target index position이 존재할 수 있습니다. 즉, 이렇게 계산된 결과는 현재 예측하고자 하는 target index의 position에 관계없이 같은 값을 갖게 됩니다. 예를 들어,
Input sequence \([x_1, x_2, x_3, x_4]\)와 index의 permutation \(Z_T = [[1,2,3,4], [1,3,2,4], … [4,3,2,1]]\) 에 대해 학습을 진행한다고 가정해 보겠습니다.
- [2,3,1,4]의 경우 \(p(x_1 \mid x_2, x_3)\)을 계산하기 위해 \(h_{\theta}(x_2, x_3)\) 과 같은 representation을 이용합니다.
- [2,3,4,1]의 경우에도 \(p(x_4 \mid x_2, x_3)\)을 계산하기 위해 \(h_{\theta}(x_2, x_3)\) 과 같은 representation을 이용합니다.
- 결과적으로 같은 representation을 이용하여 \(x_4\)과 \(x_1\)을 예측해야 하는 문제가 발생합니다.
이 문제점을 해결하기 위해서 이전의 context token들의 정보 (\(x_{z<t}\)) 뿐만 아니라 target index의 position 정보 (\(z_t\))도 함께 이용하는 새로운 Target Position-Aware Representation을 제안합니다: \(h_{\theta}(x_{z<t}) \rightarrow g_{\theta}(x_{z<t}, z_t)\).
Architecture: Two-Stream Self-Attention for Target Aware Representation
이제 target position 정보를 추가적으로 이용하는 \(g_{\theta}\)를 어떻게 구성할지의 문제가 남아 있습니다. 그에 앞서, \(g_{\theta}\)의 조건은 다음과 같습니다.
- 특정 시점 \(t\)에서 target position \(z_t\) 의 token \(x_{z_t}\)을 예측하기 위해, hidden representation \(g(x_{z<t}, z_t)\)는 \(t\) 시점 이전의 context 정보 \(x_{z<t}\) 와 target position 정보 \(z_t\) 만을 이용해야 합니다.
- 특정 시점 \(t\) 이후인 \(j \space (> t)\) 에 해당하는 \(x_{z_j}\) 를 예측하기 위해, hidden representation \(g(x_{z<t}, z_{t})\) 가 \(t\) 시점의 content인 \(x_{z_t}\) 를 인코딩해야 합니다.
Standard transformer는 각 layer에서 한 token당 하나의 representation을 갖는 구조입니다. 이 구조는 위의 두 조건을 동시에 만족시킬 수 없습니다. 1번 조건에 따르면 \(t\) 시점의 hidden representation은 \(t\) 시점의 context를 포함할 수 없지만 2번 조건에 따르면 \(t\) 시점 이후에 hidden representation을 계산하기 위해서는 \(t\) 시점의 hidden representation을 이용해야하는데, 이는 \(t\) 시점의 context를 포함해야합니다. 이와 같은 문제를 해결하기 위해서, 저자들은 2개의 hidden representation을 이용하는 변형된 transformer 구조를 제안합니다.
Query Representation: $g_{\theta}(x_{z_{<t}},z_t )$
현재 시점을 제외한 이전 시점 token들의 content와 현재 시점의 위치정보를 이용하여 계산되는 representation 입니다. 마지막 layer의 Query Representation을 이용하여 현재 position의 token을 예측하는 pre-training objective를 계산합니다. 첫번 째 layer의 Query Stream은 random trainable variable (\(w\))로 초기화 하고 최종 representation까지의 흐름 (stream), 각 layer의 state는 다음과 같이 계산할 수 있습니다.
\[Query \space Stream: \space g_{z_t}^{(m)} \leftarrow Attention(Q=g_{z_t}^{(m-1)}, KV=h_{z_{<t}}^{(m-1)};\theta)\]Qeury Stream은 Query로 이전 layer의 g state (\(z = t\)), Key, Value로 이전 layer의 h state (\(z<t\))를 이용합니다. (현재 layer의 Query Stream은 이전 layer의 g state를 attend하여 h state값들로 벡터를 재구성 합니다.) 즉, content (\(z<t\))와 위치 정보 (\(t\))만 이용하는 stream 입니다. 이 representation을 통해 위의 1번 조건을 만족할 수 있습니다.
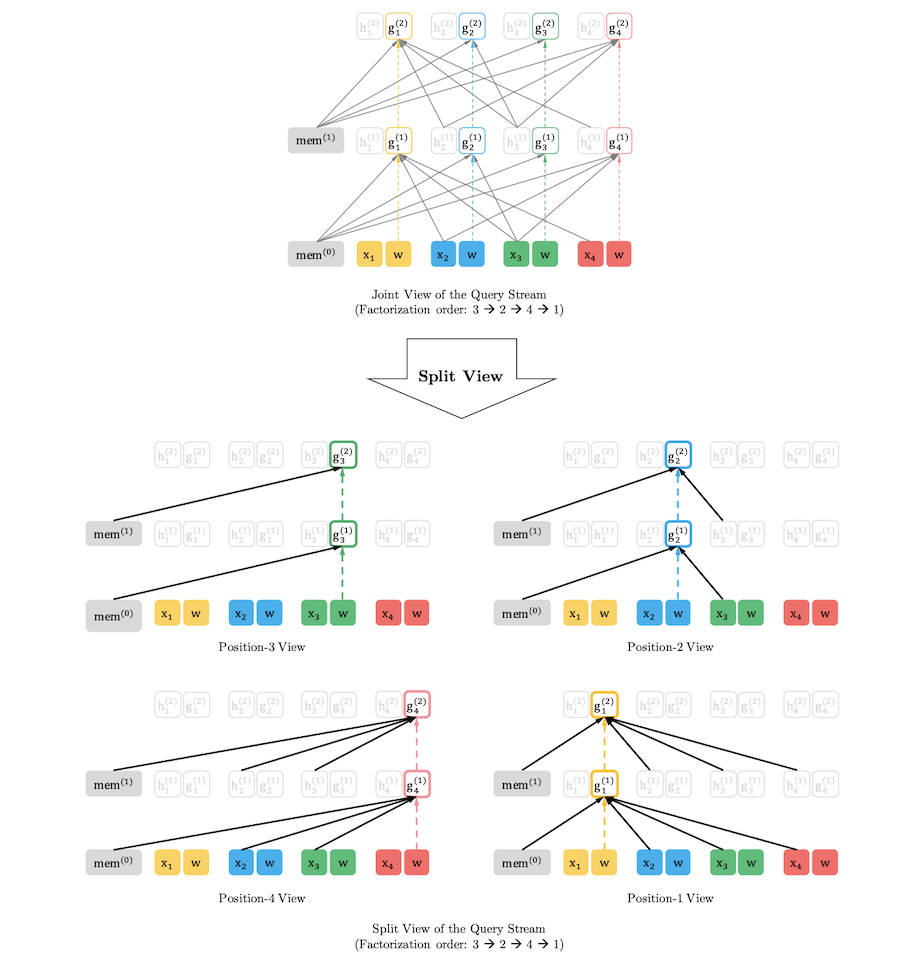
Context Representation: $h_{\theta}(x_{z \leq t})$
현재 시점 및 이전 시점 token들의 content를 이용하여 계산되는 representation 입니다. Standard transformer의 hidden state와 동일한 역할을 합니다. 첫 번째 layer의 content stream은 해당 위치 token의 word embedding으로 초기화 하고 최종 representation까지의 흐름 (stream), 각 layer의 state는 다음과 같이 계산할 수 있습니다.
\[Content \space Stream: \space h_{z_t}^{(m)} \leftarrow Attention(Q=h_{z_t}^{(m-1)}, KV=h_{z_{\leq t}}^{(m-1)};\theta)\]Content Stream은 Query로 이전 layer의 h state (\(z=t\)), Key, Value로 이전 layer의 h state (\(z≤t\))를 이용합니다. 표준 transformer의 Self Attention과 Q, K, V가 같고 \(t\) index 이후 token의 state들은 masking하여 연산을 진행합니다. 따라서 이후 step에서 이 hidden state를 이용하면, \(z > t\) 인 위치에서 \(g\)를 계산할 때, \(t\)의 context를 이용할 수 있고 따라서 위의 2번 조건 만족할 수 있습니다.
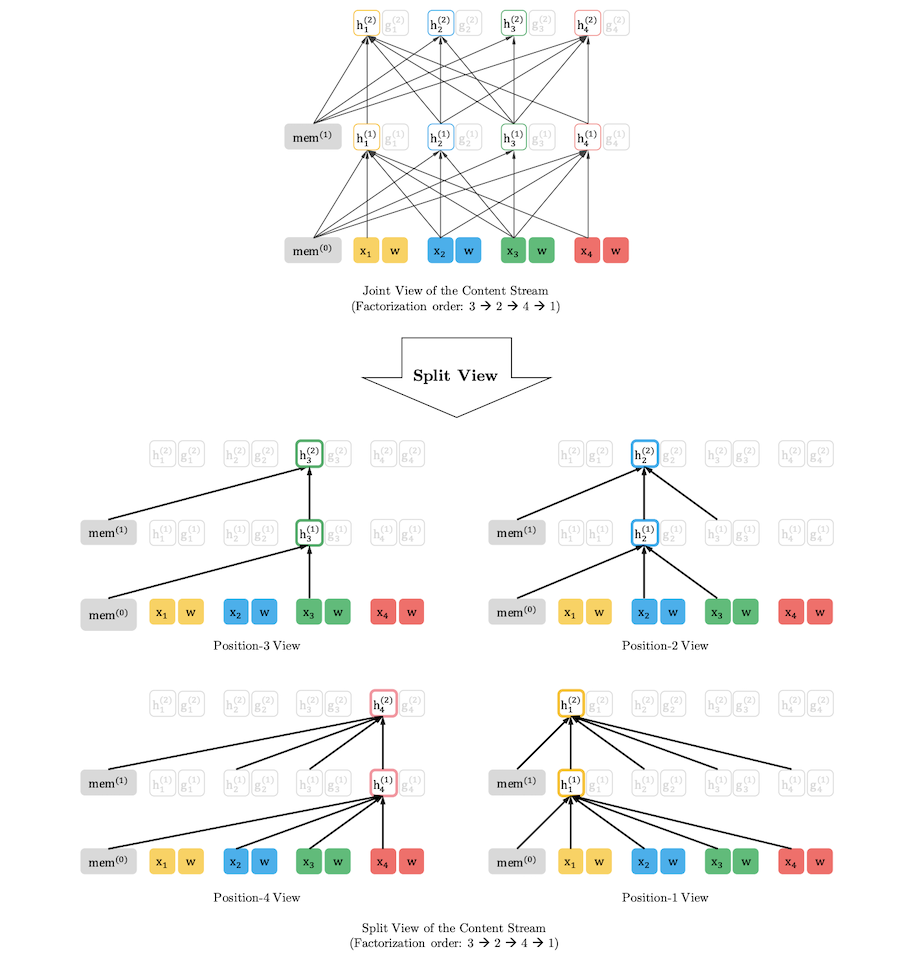
Partial Prediction
소개된 Objective는 Permutation을 이용하여 모든 조합의 순서로 Maximum Likelihood를 수행합니다. 하지만 이는 학습 시에 느린 수렴을 유발합니다. 이러한 Optimization difficulty를 극복하기 위해, 저자들은 특정 순서에서 마지막 몇 개의 예측만 이용하는 방법을 사용했습니다. 예를 들어, 3 → 2 → 4 → 1 의 순서에서 마지막 2개만 예측에 이용한다면 다음과 같습니다.
\[p(x_3) p(x_2 \mid x_3) p(x_4\mid x_2,x_3)p(x_1 \mid x_3,x_2,x_4) \rightarrow p(x_4\mid x_2,x_3)p(x_1 \mid x_3,x_2,x_4)\]Incorporating Ideas from Transformer-XL
XLNet은 긴 문장에 대한 처리를 위해 Transformer-XL (Dai et al., 2019)에서 사용된 2가지 테크닉을 차용합니다. 첫 번째는 Relative Positional Encoding이고 두 번째는 Segment Recurrence Mechanism입니다.
Relative Positional Encoding
Self-attention을 기반으로 하는 Transformer (Vaswani et al., 2017)는 CNN이나 RNN과 달리 단어들의 상대적 혹은 절대적 위치 정보를 직접적으로 모델링하고 있지 않습니다. 대신 input에 단어의 절대적 위치에 대한 representation (absolute positional encoding)을 추가하는 방식으로 순서에 대한 모델링을 할 수 있도록 합니다. 하지만 이런 absolute positional encoding 방법은 하나의 segment 내에서는 위치에 대한 의미를 표현할 수 있으나 Transformer-XL과 같이 여러 segment에 대해 recurrent 모델링을 하는 경우 문제가 있습니다. 다음의 식은 Segment-level의 Recurrence를 수학적으로 표현한 것입니다.
\[\begin{equation} \begin{split} h_{\tau+1} = f(h_{\tau}, E_{s_{\tau+1}} + U_{1:L} )\\ h_{\tau} = f(h_{\tau-1}, E_{s_{\tau}} + U_{1:L} ) \end{split} \label{eq:1} \end{equation}\]위 수식에서 \(\tau\) 는 segment의 순서(index)를 의미하고 \(E_{s_{\tau}} \in \mathbb{R}^{L \times d}\) 는 input 문장 \(s_{\tau}\) 의 word embedding이고 \(f\) 는 transformation function을 의미합니다. 즉, 첫 번째 식은 \(\tau+1\) 번째 segment의 문장 \(s_{\tau+1}\) 에 대해서, 두 번째 식은 \(\tau\) 번째 segment의 문장 \(s_{\tau}\) 에 대해서 hidden state를 구하는 것입니다. 이때 두 식에서 사용하는 input을 주목해야 하는데요, word embedding \(E\) 의 경우 segment 순서에 맞춰서 알맞게 들어간 것을 알 수 있으나 문제는 \(U_{1:L}\) 입니다. 분명히 \(\tau\) 번째 segment에 속한 단어들의 position은 에 \(\tau+1\) 번째 segment의 단어들의 position보다 앞에 있지만 둘 다 같은 위치를 표현하는 \(U_{1:L}\) 을 사용하고 있습니다. 즉, 모델은 \(\tau\) 번째 segment의 첫 번째 단어와 \(\tau+1\) 번째 segment의 첫 번째 단어를 위치 상으로 같다고 인식할 수 있다는 것이죠 (Dai et al., 2019). 좀 더 이해를 돕기 위해 예를 들어보겠습니다. 과거(\(\tau\)) segment가 [0, 1, 2, 3]이라는 position 정보를 갖고 있을 때, 현재(\(\tau+1\)) segment는 과거의 정보를 포함한 [0, 1, 2, 3, 4, 5, 6, 7]이라는 position 정보를 사용하도록 되어야 하지만 위의 식대로 하게 되면 [0, 1, 2, 3, 0, 1, 2, 3]을 사용하게 되는 것이죠. Transformer-XL과 XLNet은 이런 multiple segments에서의 absolute positional encoding에 대한 문제를 해결하기 위해, input-level이 아닌 self-attention mechanism에서 relative positional encoding이라는 단어 간의 상대적 위치 정보를 모델링하는 기법을 제안 및 사용하였습니다.
-
Attention score in standard Transformer
\[\begin{equation} \begin{aligned} \textbf{A}_{ij}^{abs} ={} \underbrace{\textbf{E}_{x_i}^{\top} \textbf{W}_q^{\top} \textbf{W}_k \textbf{E}_{x_j}}_{(a)} + \underbrace{\textbf{E}_{x_i}^{\top} \textbf{W}_q^{\top} \textbf{W}_k \textbf{U}_{j}}_{(b)} + \underbrace{\textbf{U}_{i}^{\top} \textbf{W}_q^{\top} \textbf{W}_k \textbf{E}_{x_j}}_{(c)} + \underbrace{\textbf{U}_{i}^{\top} \textbf{W}_q^{\top} \textbf{W}_k \textbf{U}_{j}}_{(d)} \end{aligned} \label{eq:2} \end{equation}\] -
Attention score with Relative Positional Encoding
\[\begin{equation} \begin{aligned} \textbf{A}_{ij}^{rel} ={} \underbrace{\textbf{E}_{x_i}^{\top} \textbf{W}_q^{\top} \textbf{W}_{k,E} \textbf{E}_{x_j}}_{(a)} + \underbrace{\textbf{E}_{x_i}^{\top} \textbf{W}_q^{\top} \textbf{W}_{k,R} \textbf{R}_{i-j}}_{(b)} + \underbrace{u^{\top} \textbf{W}_{k,E} \textbf{E}_{x_j}}_{(c)} + \underbrace{v^{\top} \textbf{W}_{k,R} \textbf{R}_{i-j}}_{(d)} \end{aligned} \label{eq:3} \end{equation}\]
위의 수식에서 첫 번째는 일반 Transformer의 Self-attention, 두 번째는 Relative Positional Encoding을 적용한 Self-attention에서의 attention score를 구하는 것입니다. 둘 사이에는 크게 3가지 차이점이 있습니다.
- Term \((b)\)와 \((d)\)에서 기존 absolute positional embedding \(U_j\) 를 relative positional embedding \( R_{i-j}\)로 대체합니다. \(R\) 은 learnable parameters가 아닌 sinusoid encoding matrix (Vaswani et al., 2017)입니다.
- Term \((c)\) 와 \((d)\) 에서 \(\textbf{U}_i^\top \textbf{W}_q^\top\) 를 각각 \(u^\top \in \mathbb{R}^d\)와 \(v^\top \in \mathbb{R}^d\)로 대체합니다. Query vector가 모든 query position에 대해 같기 때문에, 다른 단어들에 대한 attention bias가 query position에 상관없이 동일하게 유지되어야 합니다.
- \(\textbf{W}_k\) 를 \(\textbf{W}_{k,E}\) 와 \(\textbf{W}_{k,R}\) 로 분리합니다. 이는 content 기반의 key vector와 location 기반의 key vector를 각각 만들어내기 위한 것입니다.
결과적으로 각 term들은 다음의 직관적인 의미를 지닙니다: 1) Term \((a)\) 는 content를 기반의 처리를 하고, 2) \((b)\) 는 content에 의존한 positional bias를 잡아내고, 3) \((c)\) 는 global content bias를, 4) \((d)\) 는 global positional bias를 인코딩합니다.
Segment Recurrence Mechanism
XLNet은 Transformer-XL과 마찬가지로 긴 문장에 대해서 여러 segment로 분리하고 이에 대해서 recurrent하게 모델링을 하고 있습니다. Transformer-XL에서 제안된 segment-level recurrence를 XLNet에 적용하기 위해서 2가지 포인트에 주목하고 있습니다. 첫 번째는 어떻게 permutation setting에 recurrence mechanism을 적용할 것인지, 두 번째는 모델이 이전 segment로부터 얻어진 hidden state를 재사용할 수 있게 하는 것입니다.
이해를 돕기 위해 예시를 들어보겠습니다. 어떤 긴 문장이 \(\tilde{\textbf{x}}=\textbf{s}_{1:T}\) 와 \(\textbf{x}=\textbf{s}_{T+1:2T}\) 두 segment로 나뉘고, \(\tilde{\textbf{z}}\) 와 \(\textbf{z}\) 가 \([1 \dots T]\) 와 \([T+1 \dots 2T]\) 의 permutation이라고 해보겠습니다. 먼저 \(\tilde{\textbf{z}}\) 를 기반으로 첫 번째 segment에 대한 처리를 완료하고 각 layer \(m\) 으로부터 얻어진 content representation \(\tilde{\textbf{h}}^{(m)}\) 을 caching 합니다. 이때 다음(두 번째) segment에 대한 계산은 아래의 수식과 같이 나타낼 수 있습니다.
\[\begin{equation} h_{z_t}^{(m)} \leftarrow \text{Attention}( \textbf{Q}=h_{z_t}^{(m-1)}, \textbf{KV}=[\tilde{\textbf{h}}^{(m-1)}, \textbf{h}_{\textbf{z} \leq t}^{(m-1)}]; \theta) \label{eq:4} \end{equation}\]이때 \([., .]\)은 concatenation을 의미합니다. 식에서 알 수 있듯이 한번 \(\tilde{\textbf{h}}^{(m)}\) 를 이전 segment 처리에서 계산하고 나면 \(\tilde{\textbf{z}}\) 와 독립적으로 현재 segment (\(\textbf{z}\))에 대한 attention update 계산이 이루어집니다. 이를 통해 과거 segment에 대한 factorization order를 고려하지 않고 memory의 caching과 reusing이 가능한 것입니다. Query stream (\(\textbf{g}_{z_t}^{(m)}\)) 대해서도 같은 방법으로 계산할 수 있습니다.
Modeling Multiple Segments
XLNet을 어떻게 multiple segment에 대해서 autoregressive하게 모델링하고 학습시켰는지 알아보겠습니다.
Pre-training
Input은 BERT와 유사하게 [A, SEP, B, SEP, CLS]의 형태로 주어집니다. 이때 SEP와 CLS는 스페셜 token이고, Segment A와 Segment B에 들어가게 될 두 개의 문장(segment)를 랜덤으로 샘플링합니다. 그리고 두 Segment의 문장을 하나로 합쳐(concat) permutation을 수행합니다. 또한 XLNet-Large는 next sentence prediction을 효과가 별로 없어서 objectives로 사용하지 않았습니다.
Relative Segment Encoding
BERT는 absolute segment embedding을 사용하지만 XLNet은 relative position encoding과 비슷한 원리로 relative segment encoding을 적용하였습니다. 전체 sequence에서 주어진 position \(i\), \(j\) 가 같은 segment라면 \(s_{ij}=s_+\) , 아니면 \(s_{ij}=s_-\) 를 사용하며, \(s_+\) 와 \(s_-\) 는 각 attention head에 존재하는 학습가능한(learnable) paramenters입니다.
이를 통해 2가지 이득이 있는데, 첫 번째는 relative encoding의 inductive bias가 generalization을 향상시킨다는 것이고, 두 번째는 둘 이상의 segment를 갖는 fine-tuning 테스크에 대한 가능성을 열어줬다는 것입니다.
Discussion and Analysis
-
Comparison with BERT
예를 들어, [New, York, is, a, city] 라는 문장(sequence of words)가 주어졌을 때, BERT와 XLNet 모두 예측할 token으로 [New, York], 2개를 선택하여 \(\log p(\textit{New York}\;\vert\;\textit{is a city})\) 를 maximize 해야 하는 상황이라고 해보겠습니다. 이때 BERT와 XLNet의 objectives를 수식적으로 나타내면 다음과 같습니다. (여기서 XLNet의 factorization order는 [is, a, city, New, York]라고 가정합니다.)
\[\begin{equation} \begin{split} \mathcal{J}_{BERT} = \log p(\textit{New}\;|\;\textit{is a city}) + \log p(\textit{York}\;|\;\textit{is a city}),\\ \mathcal{J}_{XLNet} = \log p(\textit{New}\;|\;\textit{is a city}) + \log p(\textit{York}\;|\;\boldsymbol{New}, \textit{is a city}) \end{split} \label{eq:5} \end{equation}\]위의 수식에서 알 수 있듯이, XLNet의 경우 New 와 York 사이의 Dependency를 잡아낼 수 있지만 BERT는 이런 케이스에 대한 Dependency를 잡아낼 수 없습니다. 한 마디로 XLNet의 경우 AR LM들과 같이 이전 target들이 반복적으로 보강되어 이후 target을 예측하는데 도움을 줄 수 있지만 BERT는 그렇지 못하다는 단점이 있습니다.
-
Comparison with Language Model
OpenAI GPT (Radford et al., 2018) 와 같은 AR LM 류의 모델들은 과거에 대한 dependency만을 고려할 수 있다는 치명적인 단점이 있습니다. 예를 들어, 위의 수식에서 BERT와 XLNet의 경우 York 을 예측하는데 있어서 미래의 context인 is a city 를 활용하였으나, AR LM의 경우 오직 New 만 가지고 York 을 예측해야 한다는 한계점이 존재합니다. 이는 Question Answering (QA)과 같이 span extraction을 하는 문제에서 취약할 수 있습니다. 예를 들어 “Thom Yorke is the singer of Radiohead“라는 context에 대해서 “Who is the singer of Radio head“라는 질문에 답을 해야 하는 상황일 때, AR 모델은 “Thom Yorke“의 represenation은 “Radiohead“를 고려하기 힘들고 알맞은 답을 내놓기 어려울 수 있습니다.
ELMo (Radford et al., 2018) 의 경우 양방향에 대한 모델링은 가능하지만 shallow하기 때문에 충분히 deep interaction을 학습하기 어렵습니다.
3. Experiments
Pre-training and Implementation
Pre-training을 위해서 XLNet도 BERT를 따라서 합이 16GB 정도 되는 BooksCorpus와 English Wikipedia를 사용하였습니다. 거기에 추가적으로 Giga5, Clue Web2012-B, Common Crawl dataset도 사용하였습니다. Giga5는 16GB, 그리고 나머지 두 dataset은 너무 짧거나 질이 떨어지는 문장을 휴리스틱하게 필터링하는 전처리 작업을 하여 최종적으로 19GB와 78GB을 사용하였습니다. Google의 SentencePiece tokenizer를 사용하였고 위의 5개의 dataset 각각 순서대로 2.78B, 1.09B, 4.75B, 4.30B, 19.97B 개의 token을 얻을 수 있었고, 따라서 총 32.89B의 token으로 pre-training을 진행하였습니다.
XLNet-Large는 512 TPU v3 환경에서 2.5일 동안 약 500K step을 돌며 학습되었습니다. Batch size는 2048이었으며, Linear learning rate decay를 적용한 Adam optimizer를 사용하였습니다. 확실히 학습 데이터 양에 비해 많은 학습을 하지 않은 것을 알 수 있습니다. 실제로 저자도 모델이 학습 데이터에 대해 underfit 하지만 학습(pre-training)을 더 하더라도 downstream 테스크에 대해서는 크게 도움이 되지 않았다고 얘기하고 있으며, 모델이 데이터 스케일을 충분히 leverage하지 못하는 것을 원인으로 추측하고 있지만, 모델이 너무 커지면 fine-tuning에서의 실용성이 떨어지기 때문에 더 크기를 키우지는 않았습니다.
Results
RACE Dataset
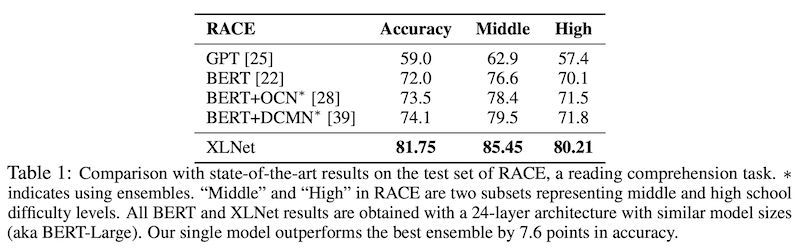
RACE dataset 100K 개의 중국 중/고등학생을 위한 질문과 전문가들이 단 정답으로 이루어져 있습니다. Reasoning에 대한 질문을 포함하는 가장 어려운 QA dataset 중 하나입니다. 게다가 평균 passage의 길이가 300을 넘고 이는 유명한 QA dataset인 SQuAD보다 깁니다. 따라서 RACE dataset은 긴 문장의 이해에 대한 척도가 될 수 있습니다. XLNet을 Sequence length를 640으로 fine-tuning 시켰으며, GPT와 BERT를 큰 격차로 outperform 하였습니다. 아무래도 dataset 자체가 전반적으로 길다보니 좀 더 큰 차이가 생기지 않았나 싶습니다.
SQuAD Dataset
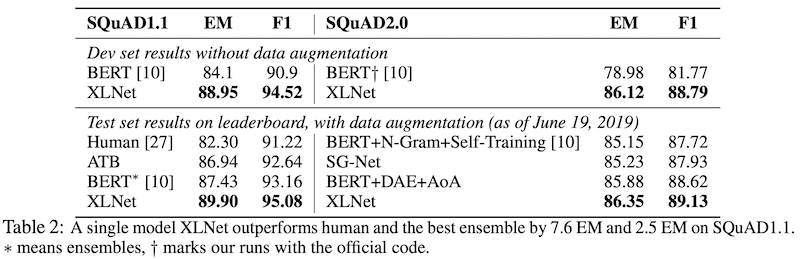
다음은 가장 유명한 QA dataset 중 하나인 SQuAD입니다. 1.1과 2.0 버전에 대해서 실험을 진행하였습니다. 마찬가지로 꽤 큰 격차의 state-of-the-art 성능을 보였습니다. 역시 문장의 길이가 비교적 긴 테스크이기에 좀 더 효과적이지 않았나 싶습니다.
Text Classification
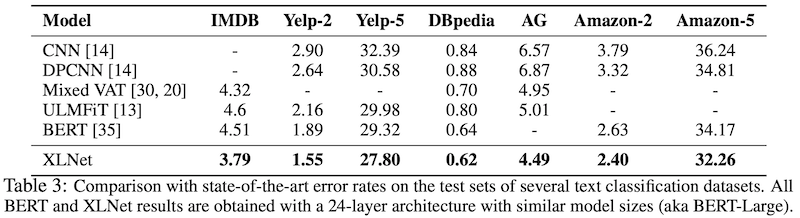
Text Classification 테스크에서 유명한 dataset에 대해서 실험을 진행하였습니다. BERT와 비교하여 IMDB, Yelp-2, Yelp-5, Amazon-2, Amazon-5에서 각각 16%, 18%, 5%, 9%, 5%의 error rate에 대한 감소를 보였습니다.
GLUE Dataset
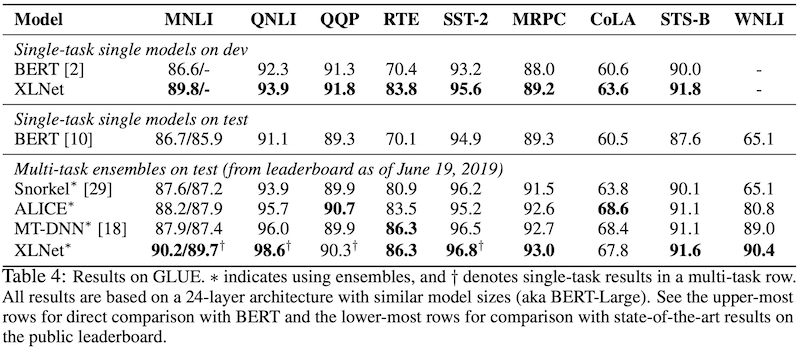
GLUE dataset은 9가지 natural language understanding에 관련된 테스크 집합입니다. Single-task learning을 통한 결과 뿐 아니라, multi-task learning에 대한 결과도 공개하였습니다. MNLI, SST-2, QNLI, QQP, 총 4개의 가장 큰 dataset으로 multi-task learning을 진행하였고, 나머지 dataset에 대해서 fine-tuning을 하였습니다. 전체 9개의 테스크 중 7개에서 state-of-the-art 성능을 얻을 수 있었습니다.
ClueWeb09-B Dataset
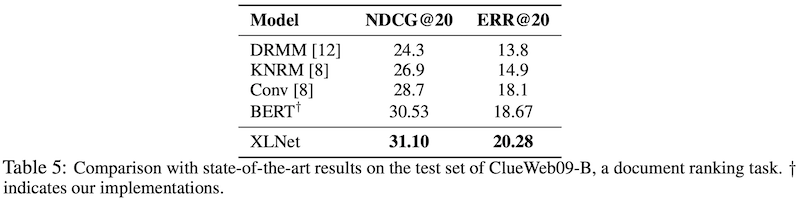
ClueWeb09-B dataset을 이용해 Document ranking에 대한 성능을 평가하였습니다. Query는 50M의 documents를 기반으로한 TREC 2009-2012 Web Tracks에 의해서 만들어졌고, 검색 결과인 top 100의 document를 reranking하는 테스크입니다. Document ranking 문제 같은 경우 주로 low-level representation이 효과를 보고 있기에 이 dataset은 XLNet word embedding의 질을 평가하는 용도로 사용하였습니다. Document와 query에 대해 fine-tuning 없이 XLNet의 word embedding을 추출하였으며, kernel pooling network (Xiong et al., 2017) 를 통해 document ranking을 하였습니다. 이 또한 기존 state-of-the-art 모델들을 outperform 하였습니다.
Ablation Study
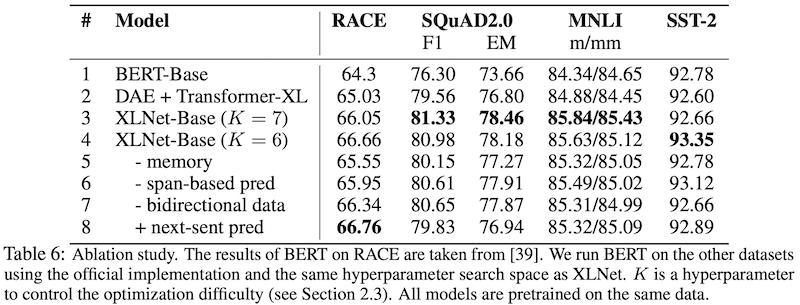
크게 다음의 3가지 측면에서 ablation study를 진행하였습니다.
- permutation language modeling objective의 효과
- Transformer-XL backbone과 segment-level recurrence (i.e. using memory)의 중요성
- span-based prediction과 bidirectional input pipeline, 그리고 next sentence prediction의 필요성
먼저 제안하는 모델인 XLNet에 대해서 총 6가지 XLNet-Base의 variants (rows 3-8) 실험을 하였으며, 결과를 Table 6에서 확인할 수 있습니다. XLNet과 비교하는 모델로는 Original BERT-Base (row 1)과 BERT에서 쓰는 Denoising auto-encoding (DAE) objective로 학습하고 bidirectional input pipeline은 적용된 Transformer-XL (row 2)을 선정하였습니다. 모든 모델은 BERT-Base의 hyperparameter와 동일하게 맞춘 12 layer의 구조를 갖고 있으며, BooksCorpus와 Wikipedia로 학습(pre-training)을 합니다. 위의 모든 결과는 5번의 결과의 중간값(median)입니다.
먼저 Table 6의 1-4행을 보면 XLNet-Base 모델이 BERT와 Transformer-XL 보다 좋은 성능을 보인 것을 알 수 있습니다. 이 결과는 위에서 언급한 3가지 측면 중 첫 번째인 permutation language modeling objective의 우수성을 보여줍니다. 한편 RACE와 SQuAD2.0에서는 DAE로 학습된 Transformer-XL 조차도 BERT 보다 꽤 좋은 성능을 보입니다. 이를 통해 두 번째 측면인 Transformer-XL 계열이 긴 sequence modeling에 효과적임을 알 수 있습니다.
세 번째 측면을 확인하기 위해 적용된 method들에 대해 ablation study (row 5-8)를 진행합니다. 우선 memory caching mechanism (row 5)의 경우, 확실히 데이터 길이가 긴 RACE에서 큰 성능 저하가 있었습니다. 그리고 6-7행은 span-based prediction과 bidirectional input pipeline이 XLNet에서 중요한 역할을 한다는 것을 보여줍니다. 마지막으로 예상치 못하게 next sentence prediction이 RACE dataset을 제외하고는 오히려 성능을 떨어뜨리는 현상을 발견했습니다 (row 8). 이런 이유로 XLNet-Large를 학습할 때는 next sentence prediction을 objective로 사용하지 않았습니다.
4. Pingpong’s Review
- 기존 pre-training 모델들을 autoregressive와 autoencoding이라는 새로운 관점으로 분석하고 문제를 정의한 것이 상당히 인상적이었습니다.
- BERT 보다 좋은 representation을 학습하면서도 GPT처럼 autoregressive한 특성을 갖고 있어서 generation 테스크에서 보다 좋은 성능이 기대됩니다.
- 하지만 짧은 문장을 다루는 테스크에서는 XLNet이나 Transformer-XL가 가지는 긴 문장에 대한 이점을 충분히 활용할 수 없기 때문에, RACE나 SQuAD 만큼 dramatic한 성능 향상을 기대하긴 어려울 것 같습니다.

5. Reference
- Papers
- Articles
- https://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html
- https://www.notion.so/Transformer-XL-Attentive-Language-Models-Beyond-a-Fixed-Length-Context-19-06-23-62ecd6bfb61b47d1aa3e3a3c91fe2bae
- https://www.notion.so/XLNet-Generalized-Autoregressive-Pretraining-for-Language-Understanding-19-06-25-f4b608f11dfc4c8c8eb4c504f867d4aa
XLNet: Generalized Autoregressive Pretraining for Language Understanding
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le