EMNLP 2019 Review - 핑퐁팀이 보고, 듣고, 느낀 점
핑퐁팀이 EMNLP 2019에 가서 보았던 인상 깊었던 논문들을 리뷰해 보았습니다.






안녕하세요, 여러분! 며칠 전 핑퐁팀 ML 엔지니어들은 홍콩에서 열린 EMNLP 2019에 다녀왔습니다.
지난번 포스트에서는 EMNLP 에 Accept 된 논문 중에 관심이 있었던 페이퍼들을 학회에 가기 전에 미리 보고 리뷰를 해봤었는데요. (https://tech.scatterlab.co.kr/emnlp2019-preview/) 이번 포스트에서는 핑퐁팀이 직접 학회에 가서 보고 들은 오랄이나 포스터 세션에서 인상 깊었던 논문들을 리뷰해 보려고 합니다. 각자 흥미로웠던 포스터나 세션 자료도 찍어 왔답니다! 자 그럼 시작해 볼까요?
인상 깊었던 발표 / 포스터 / 논문
*게시된 논문 순서는 우수성이나, 흥미성과는 무관한 랜덤한 순서임을 알려드립니다!
#1 MoEL: Mixture of Empathetic Listeners
ACL 앤솔로지 링크: https://www.aclweb.org/anthology/D19-1012.pdf
Empathetic dialogue system 분야의 이전 연구들은 대부분 특정 감정에 대한 생성에 초점이 맞춰져 있었습니다. 이런 문장 생성 모델은 충분히 유창하고 적절한 답을 생성 해내고 있습니다. 하지만 이는 maximum likelihood estimation을 사용하기에 일반적이고 반복적인 답을 만들어내는 경향이 있습니다.
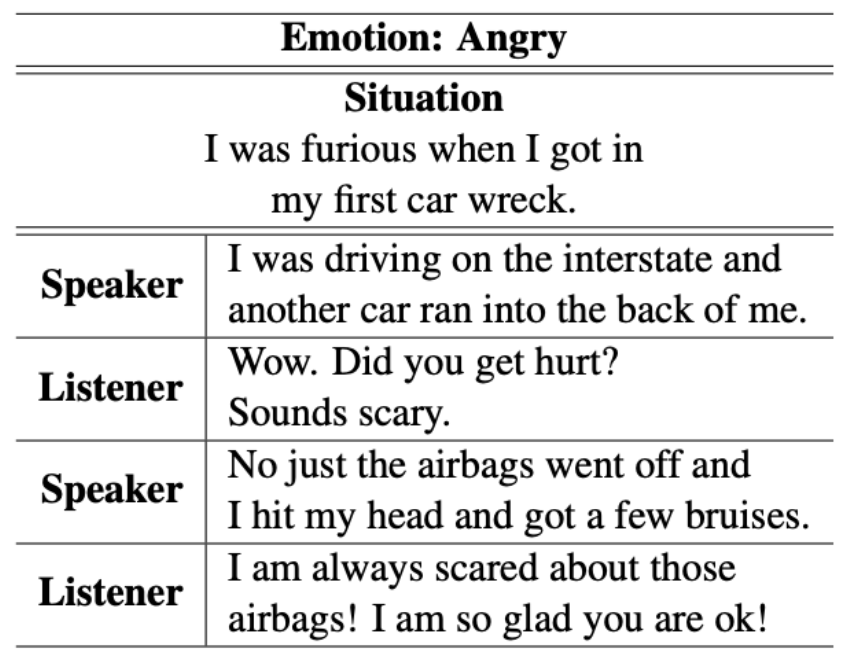
(배경) 위 예시처럼 사람은 상황과 상대방의 감정에 따라 적절하게 대답을 하게 됩니다. 상대방에게 ‘공감’하기 위해서는 감정적인 답변 자체를 만드는 능력도 필요하지만, 상대의 감정을 이해하고 그에 적절하게 대답하는 것이 더 중요한 포인트입니다. 하지만 이렇게 상대방의 감정에 공감하여 적절한 대답을 만들어내는 대화 에이전트를 학습시키는 것은 매우 어려운 일입니다.
이전 연구들에서 감정적이고 상대방에 공감하는 답변을 잘 생성해내긴 했지만, 2가지 간과한 포인트가 있었습니다.
첫 번째, 기존 연구에서는 모델을 잘 학습시키면, 그 모델이 implicit하게 감정을 이해해서 적절한 답변을 생성할 수 있다는 가정을 바탕으로 진행되었습니다. 하지만 추가적으로 감정에 대한 정보 (inductive bias)가 없다면 단일 디코더 방식은 결과가 나오게 된 원인을 파악하기 어렵고, 일반적인 답변만 내놓게 되는 문제가 발생합니다.
두 번째, 기존 연구에서는 특정한 하나의 감정을 받아서 답변이 생성된다고 가정하였습니다. 하지만 문장이 나타내는 감정은 단순하게 하나의 감정으로 나타낼 수 없습니다. 공감하는 답변을 만들기 위해 어떤 감정이 적절한지 모르기 때문에 불명확한 감정을 조건으로 받아 생성하는 것은 이상합니다.
(어떻게?) 이런 문제를 해결하기 위해서, 본 논문에서는 Mixture of Empathetic listeners (MoEL)를 제안합니다.
(Rashkin et al., 2018) 과 유사하게 대화 문맥을 인코딩해서 n개의 감정에 대한 emotional state를 만듭니다. 이 때 디코딩에서 차이점이 생기는데, 하나의 디코더를 쓰는 게 아니고 n개의 감정 각각을 위한 디코더를 n개 두고, 이들을 listeners라고 부르기로 합니다.
이 listeners는 Meta-listener와 함께 학습되게 하고, Meta-listener는 classification의 결과 분포를 기반으로 각 listener의 출력을 softly combine 합니다. 이를 통해서 모델이 감정 문맥에 대한 이해를 바탕으로 어떻게 적절한 리액션을 고를지 explicit하게 학습할 수 있습니다. (즉, 해석 가능한 결과를 내놓을 수 있습니다.)

(결과) 성능 평가를 위해 competitive baseline들과 비교 테스트를 하였고, human evaluation도 하였습니다. SOTA를 찍었으며, 분석을 통해서 MoEL이 효과적으로 올바른 listener에 집중하고 있다는 걸 보였습니다. 또한 모델이 각 emotion에 어떻게 대응하는 게 알맞은 것인지 학습했습니다. 실험 결과를 통해 볼 때, 기존 연구에서 발전된 해석 가능한 생성 모델이라 생각합니다.
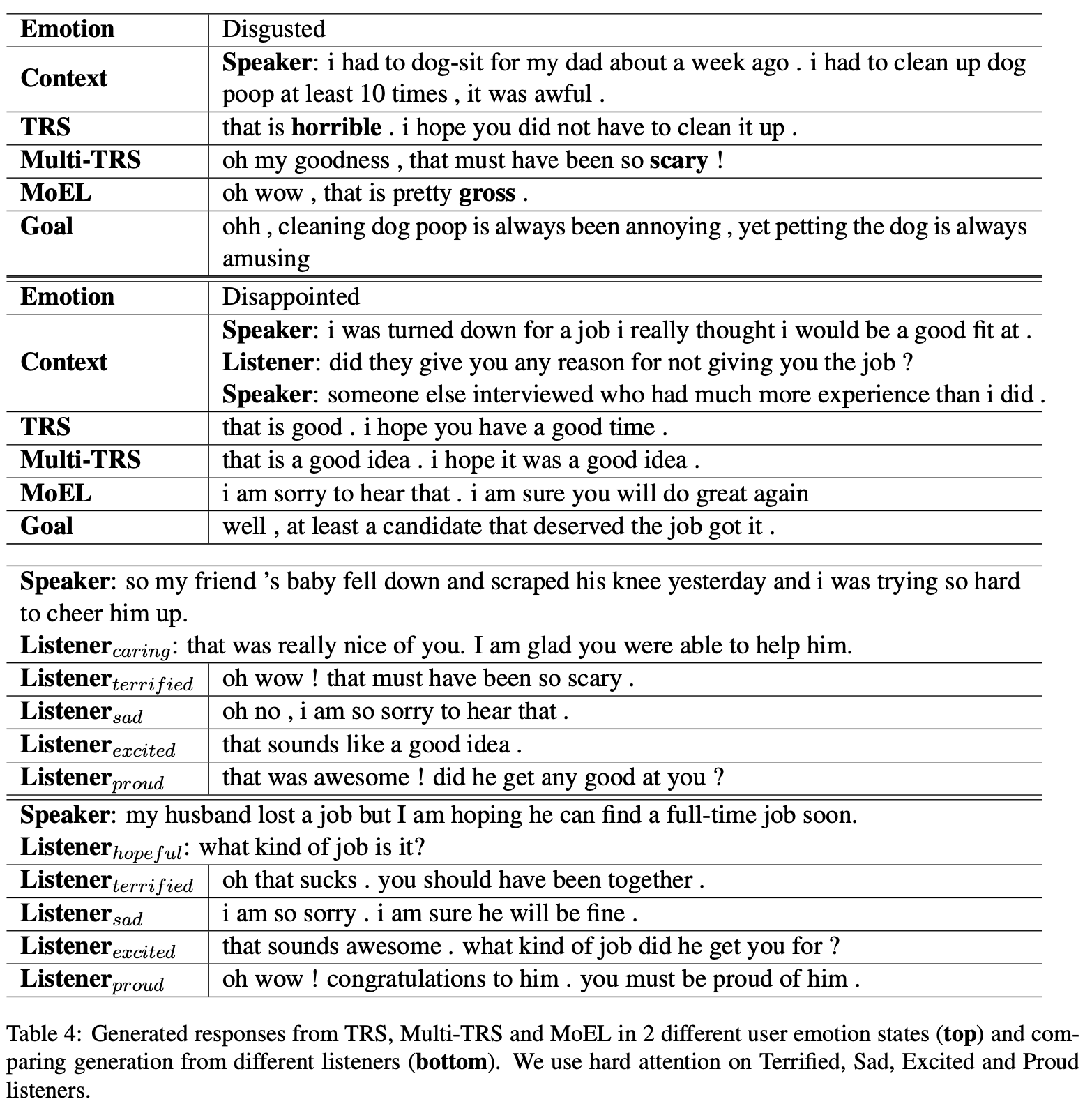
BLEU, Human Rating, Human A/B Test를 통해서 평가를 진행하여 좋은 결과를 얻었으며, 다양한 분석을 통해 감정 상황에 적절한 발화를 생성해냈다는 것을 보였습니다.
(개인적인 견해) 결과 분석이 상당히 인상적이었으며, 일상대화를 위한 대화 시스템인 핑퐁을 만들면서 정말 중요하다고 생각하는 부분에 대한 state-of-the-art 연구여서 흥미로웠습니다. Empathy, Emotion 분야에 대한 흥미를 느끼고 가능성을 볼 수 있었으며, 핑퐁의 발전에 기여를 할 수 있을 거라 생각합니다.
#2 LXMERT: Learning Cross-Modality Encoder Representations from Transformers
ACL 앤솔로지 링크 https://www.aclweb.org/anthology/D19-1514/
(배경) 이전까지의 Vision, NLP 분야의 연구 각각에서는 large-scale pre-training 이후의 fine-tuning 학습 방법이 큰 효과를 보여줄 수 있다는 것이 확인되었습니다. 본 논문에서는 Vision-NLP를 동시(multi-modality)에 pre-train될 수 있으며, 이를 통해 vision-language interaction을 학습할 수 있다는 것을 보여주었습니다.
(어떻게?)
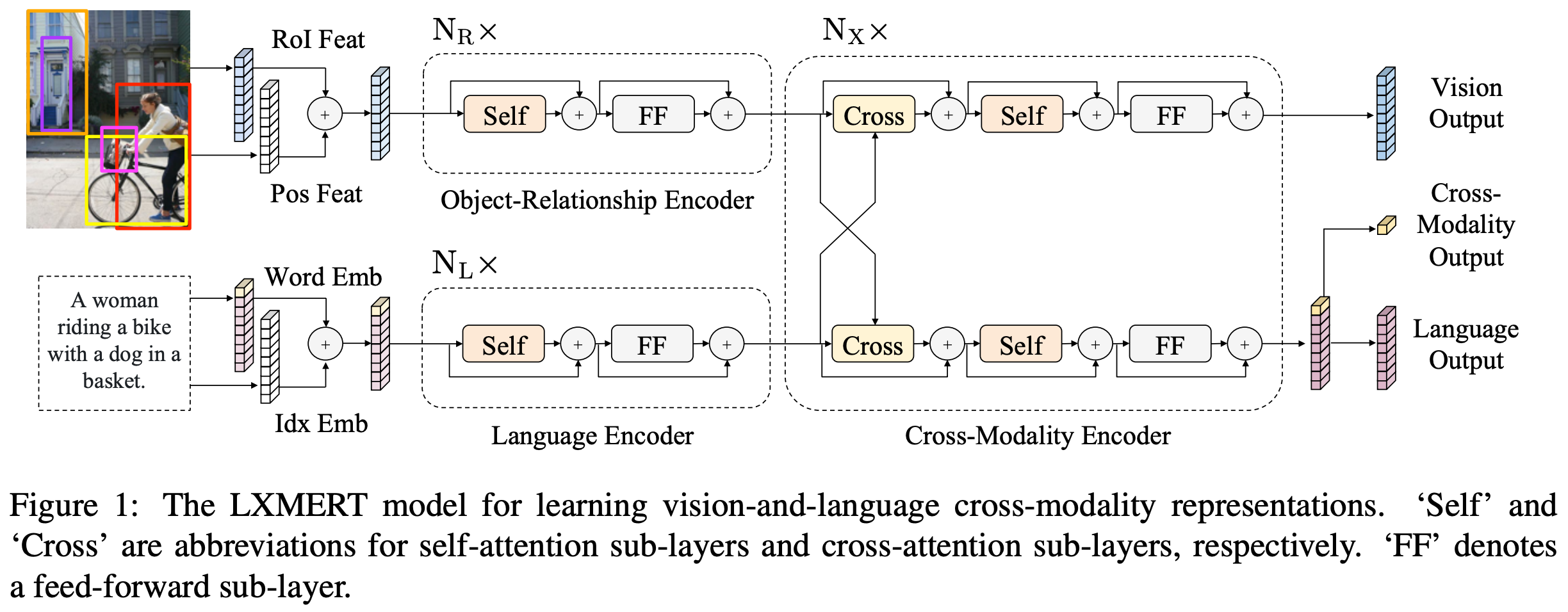
- 3개의 Transformer Encoder를 이용하였습니다 (Fig. 1 참조)
- Object Relationship Encoder: Object detector의 출력으로 나온 feature map + position을 이용하여 각 물체를 입력으로 하여 물체 간의 관계를 모델링하는 Transformer encoder를 사용하였습니다.
- Language Encoder: BERT와 동일하게 입력 텍스트에 대해 각 토큰들의 관계를 모델링하는 Transformer encoder를 사용하였습니다.
- Cross-modality Encoder: vision → language, language → vision으로의 cross-attention + self attention으로 이루어진 Transformer encoder를 사용하였습니다.
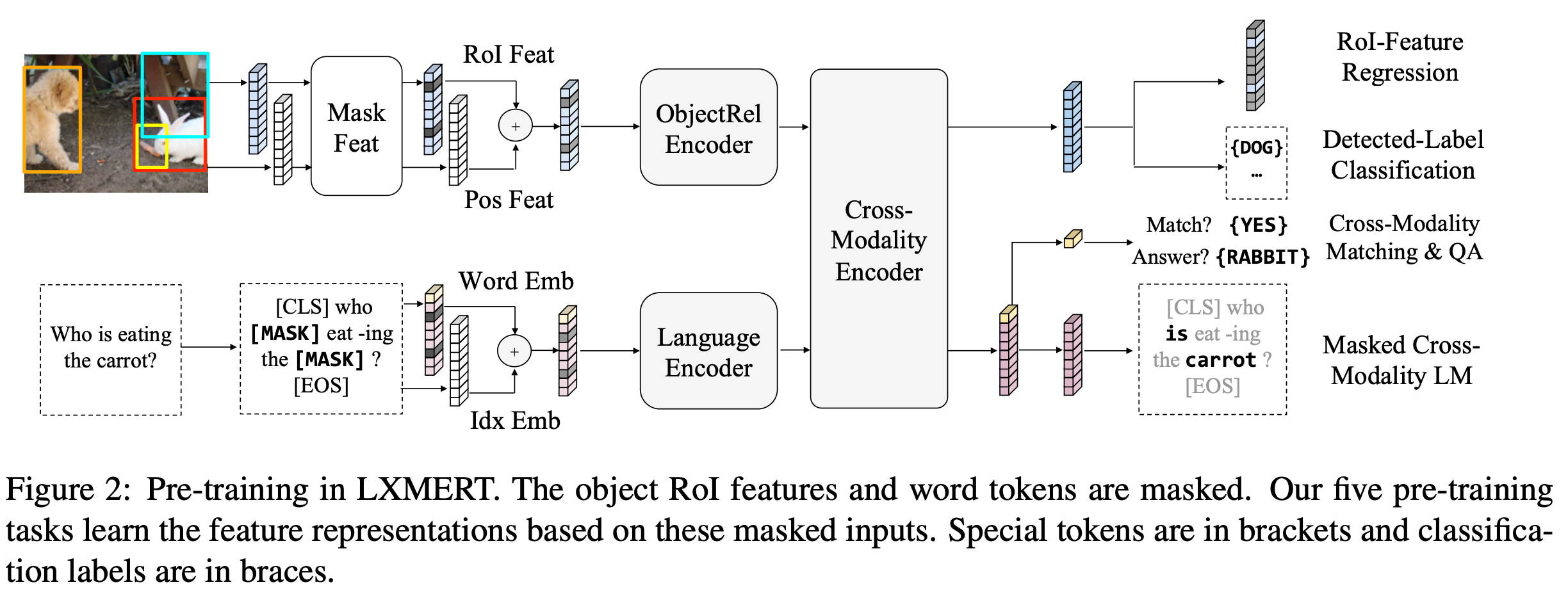
- Pre-training objective (Fig. 2)
- masked cross-modality language modeling: BERT와 비슷하게 입력 문장에 Masking을 하고 이를 맞추는 문제를 풀었습니다. (구조 상 시각 정보도 함께 이용하여 풀게 됩니다.)
- masked object prediction via RoI-feature regression: Vision의 ROI feature를 masking하고 이 feature vector 자체를 맞추는 문제를 풀었습니다.
- masked object prediction via detected-label classification: Masking된 물체의 label을 맞추는 문제를 풀었습니다.
- cross-modality matching: 이미지 - 텍스트 쌍에서 0.5의 확률로 텍스트를 다른 텍스트로 치환하고, 이미지와 텍스트가 매칭되는지에 대한 이진 분류 문제를 풀었습니다.
- image question answering: pre-training 데이터 중 QA set을 이용해서 QA문제를 풀었습니다. (이미지와 텍스트가 매칭 되는 경우에만 해당합니다.)
(결과) 두 개의 VQA benchmark에서 SOTA를 달성 했습니다. 이 논문이 인상적이었던 이유는 다음과 같습니다. 첫째, 이 논문에서는 Transformer + 제시한 pre-training objective로 Cross-modality를 학습해서 Multi-modal 환경에서 self-supervised learning 방법을 시도하였는데, 서로 다른 종류의 데이터인 이미지와 텍스트를 함께 학습했음에도 학습이 잘 이루어지고, 이를 통해 성능 향상을 이끌어낸 점이 신기했습니다. 앞으로 이 방향의 연구가 지속적으로 발전해 나갈 것 같습니다.
둘째로, 또 하나 인상적이었던 점은 실험 결과에서 다양한 조건으로 pre-training을 진행하고 이를 비교했다는 점으로, 각 이미지와 언어 데이터가 작업에 어떻게 기여하는 지를 간접적으로나마 알 수 있었습니다. 예를 들어 Language쪽 encoder를 BERT로 초기화 했을 때 오히려 성능이 떨어짐을 볼 수 있었는데, 이를 통해 Single-modality는 해당 영역에서만 잘 동작함을 볼 수 있었습니다.
#3 Learning with Noisy Labels for Sentence-level Sentiment Classification
ACL 앤솔로지 링크 https://www.aclweb.org/anthology/D19-1655.pdf
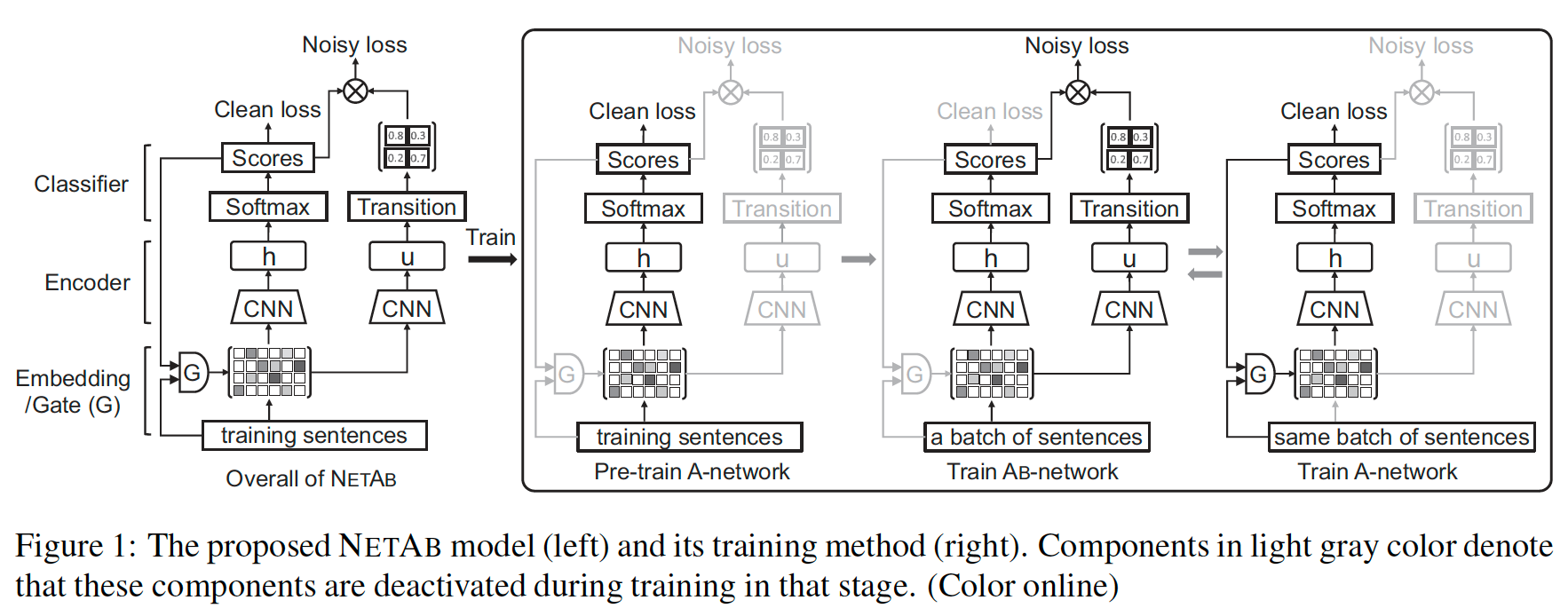
(배경) 일반적으로 노이즈를 포함하고 있는 데이터셋을 학습에 이용하고, clean label 데이터로 inference를 하면 inference 성능이 크게 떨어집니다. 이 논문은 noisy label을 포함한 데이터를 학습 데이터로 이용할 때, CNN 기반의 Sentence-level Sentiment Classification Model을 큰 성능 하락 폭 없이 학습시키는 방법을 제안한 논문입니다.
이 논문에서는 크게 2개의 가설을 바탕으로 하고 있습니다. 첫째, DNN은 쉬운 예시를 먼저 기억한 뒤, 학습 epoch이 증가함에 따라 점점 어려운 예시를 기억해 나간다. 둘째, noisy label은 어떠한 noise transition matrix에 의해 clean label로부터 변경된 것이다.
(어떻게?) 그림과 같이 2개의 CNN으로 구성된 모델 NET-AB를 제안했습니다. 총 2개의 CNN 모델로 이루어져 있어, 한 모델은 ‘clean’ label을 예측하는 sentiment score를 학습하는 모델 (A-network)이고, 다른 한 모델은 noise transition matrix를 추측하기 위한 모델(AB-network)입니다.
AB-network는 Gate unit과 clean loss를 제외하고는 A-network의 파라미터를 공유하고 있고, noisy transition matrix Q를 추측하기 위한 추가적인 transition layer를 포함하고 있습니다.
학습 과정은 다음과 같이 진행합니다. 우선, A-network를 첫 5 epoch 동안 사전 학습합니다. 그 후, AB-network와 A-network를 번갈아가면서 학습하는데, 문장 배치가 주어지면, AB-network를 우선 학습하고, A-network를 이용하여 예측한 점수를 사용하여 이 Batch 내에서 clean label을 갖는 문장을 선택하고, 선택된 문장으로 A-network를 학습합니다.
(결과) 총 두 종류의 sentence-level sentiment classification 데이터셋을 이용하여 실험을 수행했습니다. 실험 결과 모든 데이터셋에 대해서, 현저한 성능 향상을 보였습니다.
- clean-labeled 데이터셋을 의도적으로 더럽혀 noisy-label을 추가한 데이터셋 : 원 clean-labeled 데이터셋으로는 movie sentence polarity 데이터셋 (Pang and Lee, 2005)과 SemEval-2016의 노트북, 레스토랑에 관한 데이터셋을 이용했습니다.
- 실제 noisy-label을 포함하고 있는 데이터셋 : 영화, 노트북, 레스토랑의 3가지 도메인에 대한 리뷰 데이터를 추출하여 4, 5점 리뷰에 대해서는 positive, 1, 2점 리뷰에 대해서는 negative로 간주하여 데이터셋을 구성했습니다.
(이 논문이 인상 깊었던 이유) 최근에는 크라우드 소싱을 이용하여 수집한 데이터셋을 이용하거나, unlabeled 데이터셋으로부터 소량의 레이블을 활용하여 만든 데이터셋을 이용하는 경우가 많아지고 있습니다. 이런 경우 대량의 데이터를 수집할 수 있다는 장점이 있지만, 데이터셋의 질이 떨어져 손수 noisy한 레이블을 수정하거나, 이러한 데이터셋에 적합한 모델링 방법을 고안할 필요가 있습니다. 저는 이 논문이 이러한 최근 경향을 잘 반영한 논문이라고 생각하고, 직관적으로 이해할 수 있는 방법론을 이용하여 확실한 성능 향상을 얻었다는 점을 높이 평가했습니다.
#4 Neural data-to-text generation: A comparison between pipeline and end-to-end architectures
ACL 앤솔로지 링크 https://www.aclweb.org/anthology/D19-1052.pdf
(배경) 기존의 자연어 문장 생성 프로그램들은 여러 모듈들이 결합된 파이프라인(Pipeline) 형태로 구성되어 있었습니다. 다시 말해서, 하나의 큰 문장 생성이라는 작업을 여러 세부 작업들로 쪼개어서 진행하였던 것입니다. 그렇지만 최근 연구 결과들은 입력으로부터 바로 출력을 생성하는 End-to-End 구조적인 관점으로 문장 생성을 시도하고 있는 추세입니다.
(어떻게?) 본 논문에서는 기존의 연구자들이 제시한 구조와 유사한 End-to-End 문장 생성모듈을 구현하고 이 모듈이 기존의 파이프라인 구조와 얼마나 성능 차이를 보이는지를 확인하였습니다. 파이프라인은 (응답 개체 순서 정하기, 텍스트 구조화, 어휘 찾기, 지시 표현 생성하기)의 4개의 세부 작업으로 설정하였습니다.
- 응답 개체 순서 정하기: 예를 들어서 “식당”과 “식당 전화번호”에 대한 응답을 생성한다고 가정해봅시다. 그렇다면 상식적으로 “식당” 이야기가 먼저 나오고 “식당 전화번호” 이야기가 나와야하는 것이 맞습니다. 응답 개체 순서 정하기는 이러한 개체의 순서를 정하는 작업입니다.
- 텍스트 구조화: 텍스트 구조화는 개체를 바탕으로 실제 문단의 구조나 문장의 구성을 템플릿 형태로 구성하는 것을 의미합니다. 예를 들어, “식당”과 “식당 전화번호” 개체에 대해서 [토큰] 식당 [토큰] [토큰] 전화번호 [토큰] 형태의 생성 전 형태로 바꾸는 작업입니다.
- 어휘찾기: 토큰 자리에 맞는 단어를 찾는 작업입니다. 실질적인 문장의 생성은 이때 이루어집니다.
- 지시표현 생성하기: he, she, it 등의 지시표현등으로 고유명사를 치환하는 작업입니다.
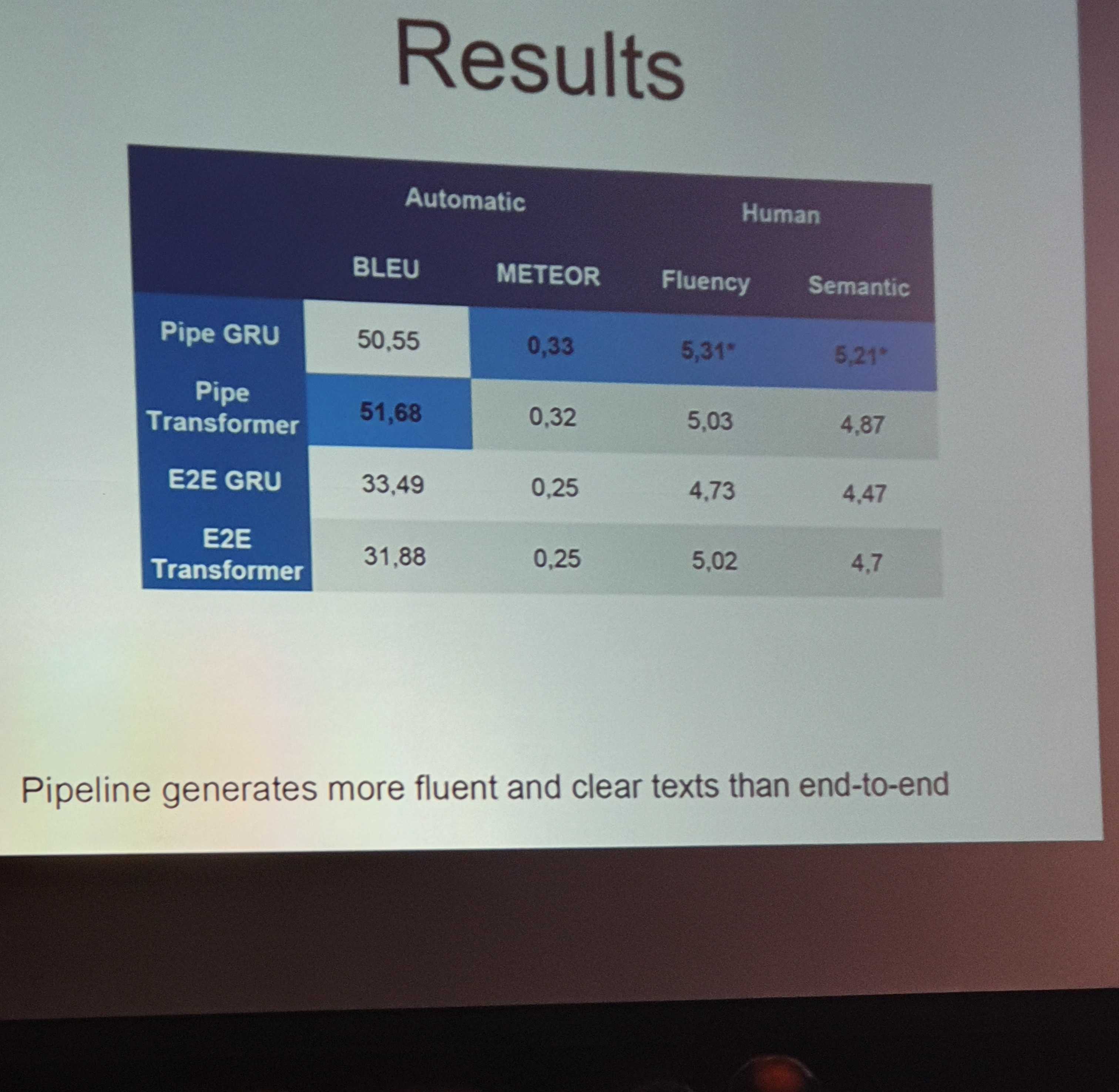
데이터는 WebNLG 데이터를 활용하였으며, BLEU와 Meteor를 측정하였습니다. 비교 대상으로써 각 모듈들은 각각 GRU와 Transformer로 구현되었습니다.
(결과) 각 세부 결과에 대해서, 서로 다른 모듈이 각기 다른 분야에서 우수한 성능을 보였습니다. GRU가 문맥 순서 정하기와 텍스트 구조화에서 더 높은 성능을 기록한 반면, 어휘 찾기 작업에서는 Transformer가 더 빼어난 성능을 보였습니다. 이는 상대적으로 쉬운 작업에 대해서는 GRU가 더 강력하다는 것을 나타냅니다.
End-to-End 모델은 파이프라인 모델에 비해 생성모듈의 성능이 낮았으며, 훈련 데이터에 등장하지 않는 도메인에서 그 하락폭이 두드러졌습니다. 특히 End-to-End 모델에서는 환상 (Hallucination) 현상이 나타났는데 이 현상은 문맥에서 다루지 않은 단어에 대해서 문장이 생성되는 것을 말합니다. 즉, End-to-End는 말은 잘 하지만, 조리있게 말을 하는 능력은 부족했다 할 수 있습니다.
(이 논문이 인상 깊었던 이유) 앞으로 대화 시스템의 개발에 있어서 End-to-End에 대한 수요는 커질 것입니다. 그렇지만 여전히 End-to-End를 단순히 큰 신경망으로 표현하는 것은 무리가 있다고 판단이 됩니다. 각 기능을 어느 수준까지 모듈화할지에 대해서 고찰했다는 점에서 이 논문의 시도가 크게 의미가 있다고 하겠습니다.
#5 Integrating Text and Image: Determining Multimodal Document Intent in Instagram Posts
ACL 앤솔로지 링크 https://www.aclweb.org/anthology/D19-1469/
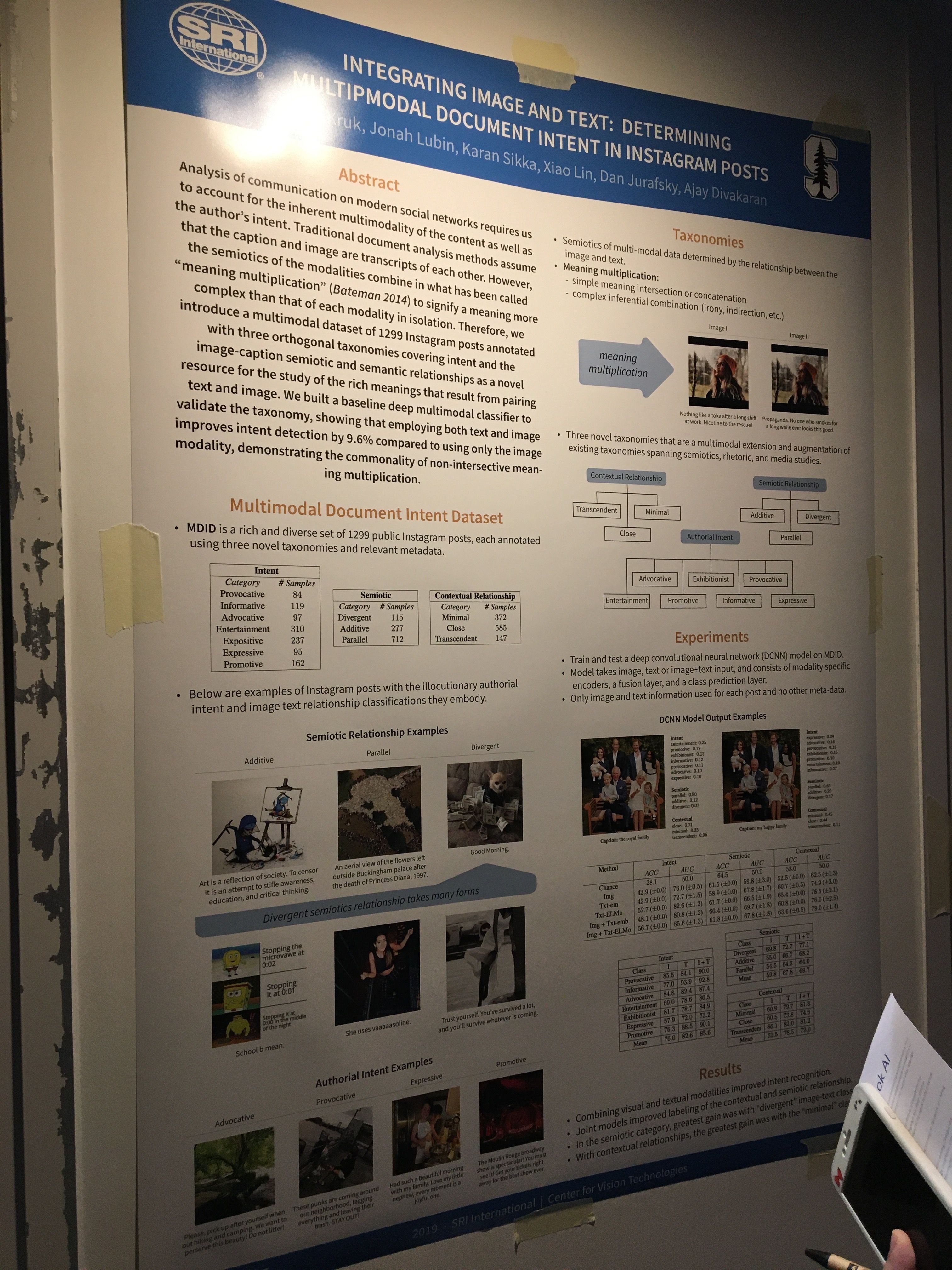
(배경) 우리가 글이나 그림을 보고 의미를 파악할 때, 종종 필자의 의도까지 고려해야 합니다. 우리가 인스타그램에 댓글을 올릴 때를 생각해 봅시다. 돌이켜 보면, 대체적으로 사진과 관련 있는 내용을 충실히 적는 경우가 많지만 농담 삼아서 별로 상관없는 내용을 적는 경우도 적지 않게 있다는 것을 알 수 있습니다. 만약 우리가 이러한 게시글에 자동으로 댓글을 달아주는 모델을 학습시키려 한다면, 과연 이미지와 텍스트만으로 이루어진 데이터로 충분할까요? 본 논문은 이 질문을 해소하는 방법을 제시하고 있습니다.
(어떻게?) 본 논문에서는 위와 같은 다중 모달 데이터에서 각 모드가 나타내는 의미 양상을 분류하는 세 가지 체계를 제안하고, 이를 바탕으로 약 1300개의 인스타그램 게시글로 구성된 MDID 데이터셋을 공개합니다. 그리고 몇 가지 간단한 분류 모델로 성능을 평가해 이를 베이스라인으로 제시합니다.
본 논문에서는 위와 같은 다중 모달 데이터에서 각 모드가 나타내는 의미 양상을 분류하는 세 가지 체계를 제안하고, 이를 바탕으로 약 1300개의 인스타그램 게시글로 구성된 MDID 데이터셋을 공개합니다. 그리고 몇 가지 간단한 분류 모델로 성능을 평가해 이를 베이스라인으로 제시합니다. 각 분류 체계를 요약하면 다음과 같습니다:
- Intent: 화자의 의도에 대한 8가지 분류(advocative, promotive, exhibitionist, expressive, informative, entertainment, provocative/discrimination, provocative/controversial)
- Contextual Relationship: 이미지와 텍스트 각각의 직접적 의미에 근거한 상관관계에 따른 3가지 분류(minimal, close, transcendent)
- Semiotic: 각 모드가 의미에 어떻게 기여하는지에 대한 기호학적 관계에 따른 3가지 분류(divergent, parallel, additive)
Contextual relationship과 Semiotic 분류 체계가 언뜻 비슷해 보일 수 있지만, 전자는 상관관계가 얼마나 있는지(크기)에 대한 분류라면 후자는 서로 어떻게 관계되는지(방향)에 대한 분류라고 이해할 수 있겠습니다. 이를 이용해 만든 실제 데이터와 실험 결과는 논문에서 직접 확인해보세요 :)
저자의 포스터 발표를 들어보니 더 큰 데이터셋도 구상하고 있다고 하는데요, 연구가 확대된다면 이미지 캡셔닝 등 관련 분야에서 더 현실적이고 어려운 문제를 풀 수 있을 거라 생각합니다. 인스타그램 데이터를 다뤄본 경험이 있어서 개인적으로 인상 깊게 본 연구였습니다.
#6 Do NLP Models Know Numbers? Probing Numeracy in Embeddings
ACL 앤솔로지 링크 : https://www.aclweb.org/anthology/D19-1534.pdf
(배경) NLP 모델에서 수사(numeracy)를 이해하고 사용하는 것은 많은 추론 태스크에서 중요한 문제입니다. 하지만 여전히 많은 NLP 모델에서는 숫자를 다른 특수 토큰(N이나 @등)으로 변경하는 방법을 사용하고 있습니다. “과연 이 토큰이 해당 수사를 이해하는데 충분할까?” 에 대한 답을 본 논문에서는 시사하고 있습니다.
(어떻게?) 본 논문에서는 숫자의 정보를 (numerical) 모델이 QA 테스크에서 잘 이해하고, 사용할 수 있는지를 조사해보는 실험을 진행하였습니다. DROP 데이터셋의 SOTA 모델을 이용해서 해당 정보를 알아보고자 하였습니다.
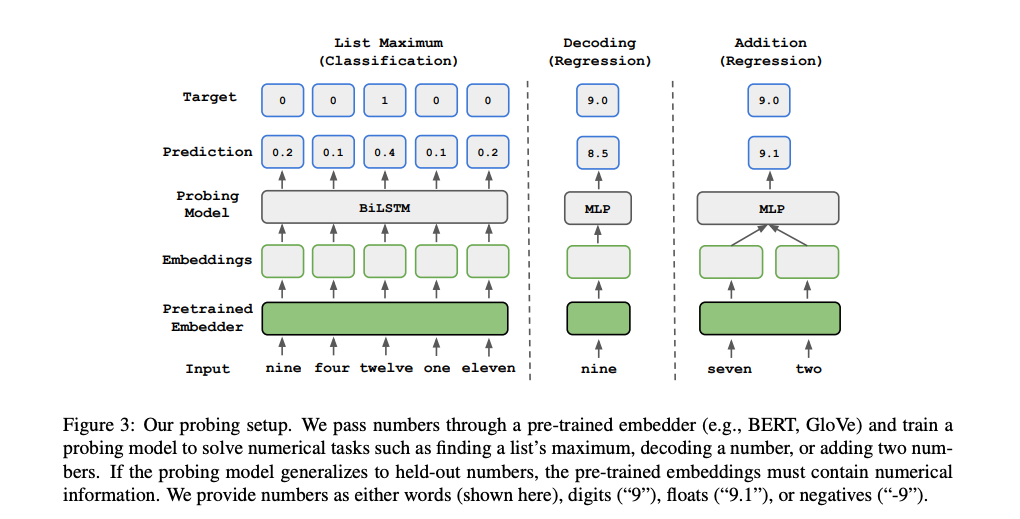
숫자를 얼마나 잘 이해하고 있는지 확인하기 위해서 총 3가지 Probing Numeracy of Embeddings 테스크를 설계해서 실험을 진행하였습니다. (List Maximum, Decoding, Addition)
- List Maximum: 5개의 다른 숫자에 대한 Embedding List(5, Embedding_Size) 를 주고, 리스트 중에서 가장 큰 숫자를 찾는 테스크 → LSTM을 이용한 SPAN-Selection 모델을 사용
- Decoding: 해당 숫자에 대한 Embedding 을 주고, 해당 숫자의 value 를 예측하는 테스크 → 간단한 linear regression 모델과 3-Layer FCNN (with ReLU) 를 사용하였으며, MSE 를 loss 로 사용
- Addition: 두 숫자 Embedding 을 input 으로 넣고 Decoding 처럼, 두 숫자의 합을 예측하도록 실험 설계 → 3-Layer FCNN (with ReLU) 를 사용하였으며, MSE 를 loss 로 사용
(결과) 전반적으로 모델들은 각 태스크에 대해서 충분히 높은 성능을 보여주었으며, 모델들이 numerical reasoning 테스크를 풀기 위한 충분한 숫자 정보를 인지하고 있다는 것을 알 수 있었습니다.
Char-CNN/Char-LSTM(ELMo): 전체적인 테스크 성능에서 가장 높은 성능을 일관적으로 보여주었습니다. 두 모델 역시 유사한 성능을 갖고 있고, CNN이냐 LSTM이냐의 요인보다는 Character Level의 팩터가 가장 큰 요소라고 생각합니다.
BERT: 가장 강력한 Pretrained Network 이지만, 숫자에서는 약했습니다. Sub-Word Level 에서 많은 손해를 보았다고 추측하였고, [0,9999] 범위의 List Maximum 테스크에서는 52%의 낮은 정확도를 보였습니다. 또한 추가 테스트에서 Float에서 취약하다는 것을 발견하였습니다.
(+추가) 월간 자연어 처리(허훈님) 페이지에서 본 논문에 대한 정리를 하신 게시물이 있습니다. 잘 정리된 좋은 게시물이기 때문에 이를 참조하셔도 좋을 것 같습니다.
마무리
지금까지 핑퐁팀 엔지니어들이 각자 흥미가 있었던 논문을 한편씩 리뷰해보았습니다.

학회를 다녀오면서 여러 지식들, 참석자들과의 네트워킹 등 여러가지를 얻을 수 있었지만, 무엇보다 새로운 아이디어나 컨셉들을 보며 “우리도 한번 해볼 수 있지 않을까?”, “우리도 이런 방식을 적용해 볼 수 있을 것 같은데?” 라는 인사이트들을 얻어간 것이 가장 큰 수확이라고 생각합니다.
EMNLP 2019 학회가 진행되는 한주간 엔지니어들에게는 많은 지식적으로, 정신적으로 힐링이 되는 행복한 시간이었습니다. 다음에 또 학회를 갈 기회가 된다면 더 자세하게 리뷰해보도록 하겠습니다.