딥러닝 모델 서비스 A-Z 2편 - Knowledge Distillation
난 선생이고 넌 학생이야



핑퐁팀이 내부적으로 활용하는 대형 언어 모델은 실제 서비스화하기에는 연산량이 많고, 많은 메모리를 요구합니다. 이런 모델을 실제로 활용하기 위해서는 잘 알려진 경량화 기법을 적용해야 하는데, 그 중 가장 대표적인 Knowledge Distillation 방법을 적용한 사례를 소개해보고자 합니다.
Knowledge Distillation이란
Knowledge Distillation은 개념을 제안한 논문(Hinton et al., 2015)을 살펴보면 자세히 이해할 수 있습니다. 큰 데이터셋에서 학습한 여러 모델을 하나의 뉴럴 넷으로 Knowledge Distillation하는 것이 효과적임을 증명한 논문입니다. 이 논문에서 아래와 같이 설명합니다.
For tasks like MNIST in which the cumbersome model almost always produces the correct answer with very high confidence, much of the information about the learned function resides in the ratios of very small probabilities in the soft targets. For example, one version of a 2 may be given a probability of \(10^{-6}\) of being a 3 and \(10^{−9}\) of being a 7 whereas for another version it may be the other way around. This is valuable information that defines a rich similarity structure over the data (i. e. it says which 2’s look like 3’s and which look like 7’s) ….
“학습이 잘 된 큰 모델의 예측은 정답을 매우 잘 맞추면서도 클래스 간의 관계 또한 잘 설명할 수 있다.”로 요약이 가능합니다. MNIST 데이터셋에서 2가 정답일 때 3과 7 또한 적지 않은 확률이 나올 텐데, 이 정보는 2, 3, 7이 서로 관련성이 크다는 것을 의미합니다. 따라서 학습이 잘 된 모델의 결과를 사용하는 것이 의미 있는 일이고, 그렇게 학습하는 것을 Knowledge Distillation이라고 이해할 수 있습니다.
이러한 생각을 기반으로 최근에는 NLP 쪽, 특히 Large-scale Language Model을 이용한 Knowledge Distillation 연구가 활발하게 이루어지고 있습니다. PKD-BERT (Sun et al., 2019), DistilBERT (Sanh et al., 2019), Turc et al. (2019), Tang et al. (2019)가 대표적인 예시로서 BERT 기반의 모델을 더 작고 실용적인 모델로 만드는 노력이 계속되고 있습니다.
실험 대상
핑퐁팀은 일상 대화 시스템을 구축하는 만큼 좋은 답변을 잘 골라내는 모델이 필요합니다. 핑퐁팀에서 Knowledge Distillation을 적용하고자 한 모델의 구조에 대해 간략하게 소개합니다.
Teacher 모델
Teacher 모델은 대화 문맥과 답변을 각각 인코딩하기 위해 두개의 BERT 인코더로 이루어진 모델입니다. 그 뒤 Faiss와 같은 라이브러리를 사용하여 ANN (Approximate Nearest Neighbor) 검색을 쉽게 하기 위해 BERT의 Hidden Size에서 고정된 차원으로 Projection하는 Feed Forward 레이어가 각각 BERT 인코더 뒤에 하나씩 존재합니다. 대화 문맥과 답변이 잘 맞는지는 각 Encoder의 결괏값 사이의 코사인 유사도를 기준으로 확인합니다.
사용한 Knowledge Distillation 방법
Prediction Logit Distillation
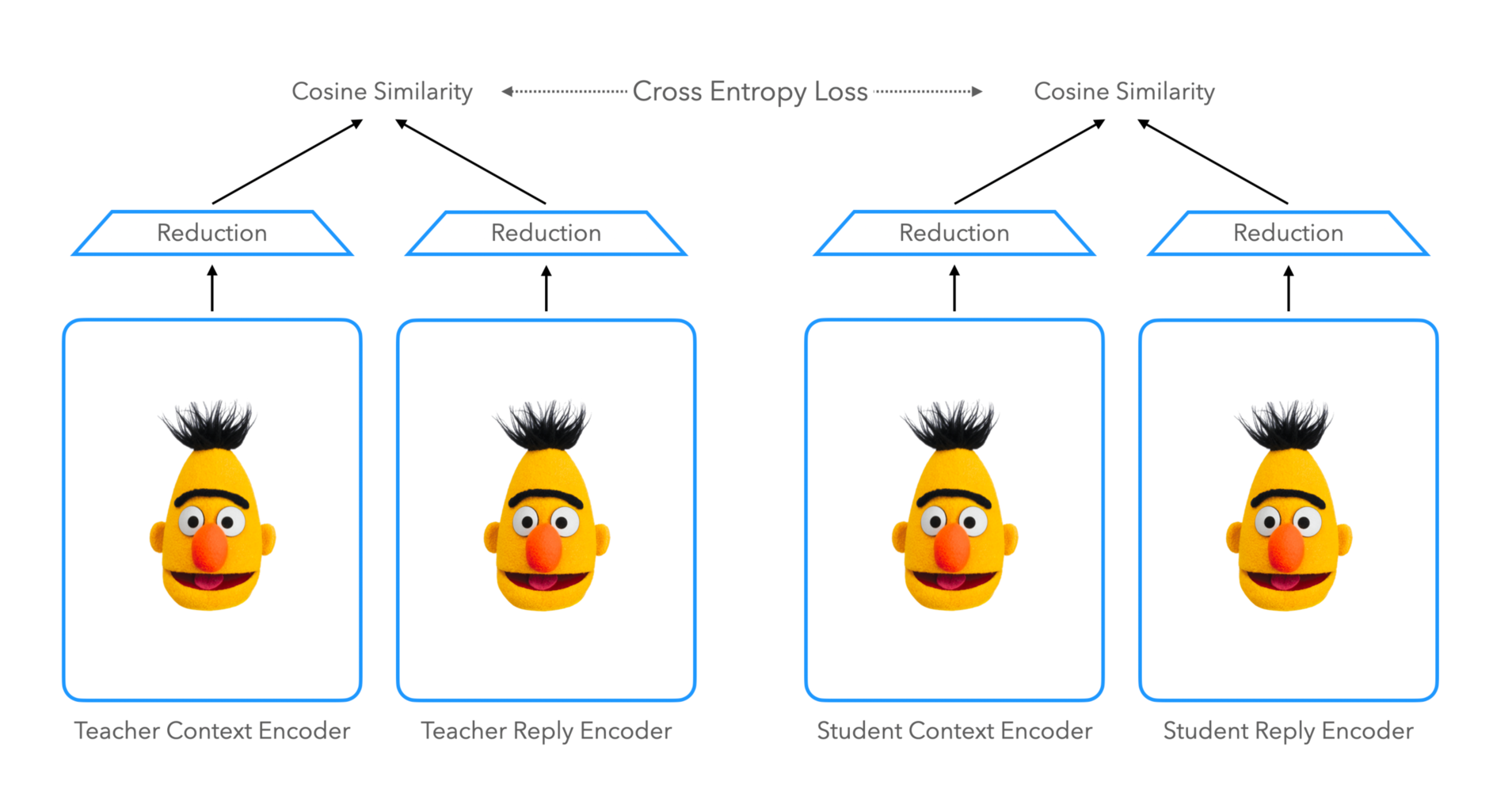
일반적인 방식의 Distillation입니다. 다만 아래 나올 방식과 다른 이름을 명확히 붙여주기 위해 Prediction Logit Distillation이라고 부르게 되었습니다. Student와 Teacher에서 만들어낸 Classification Logit을 각각 $z^S$, $z^T$라 할 때, Objective는 아래처럼 정의합니다.
\[\mathcal{L_{pred}} = \text{CrossEntropy}(\text{Softmax}(z^S / t), \text{Softmax}(z^T / t))\]Hinton et al. (2015)에서 제안한 방식대로 Temperature에 해당하는 $t$를 추가하여 Loss를 적용하였습니다. 이번 실험에서는 $t = 1$일 때 가장 잘 동작하였습니다.
Embedding Distillation
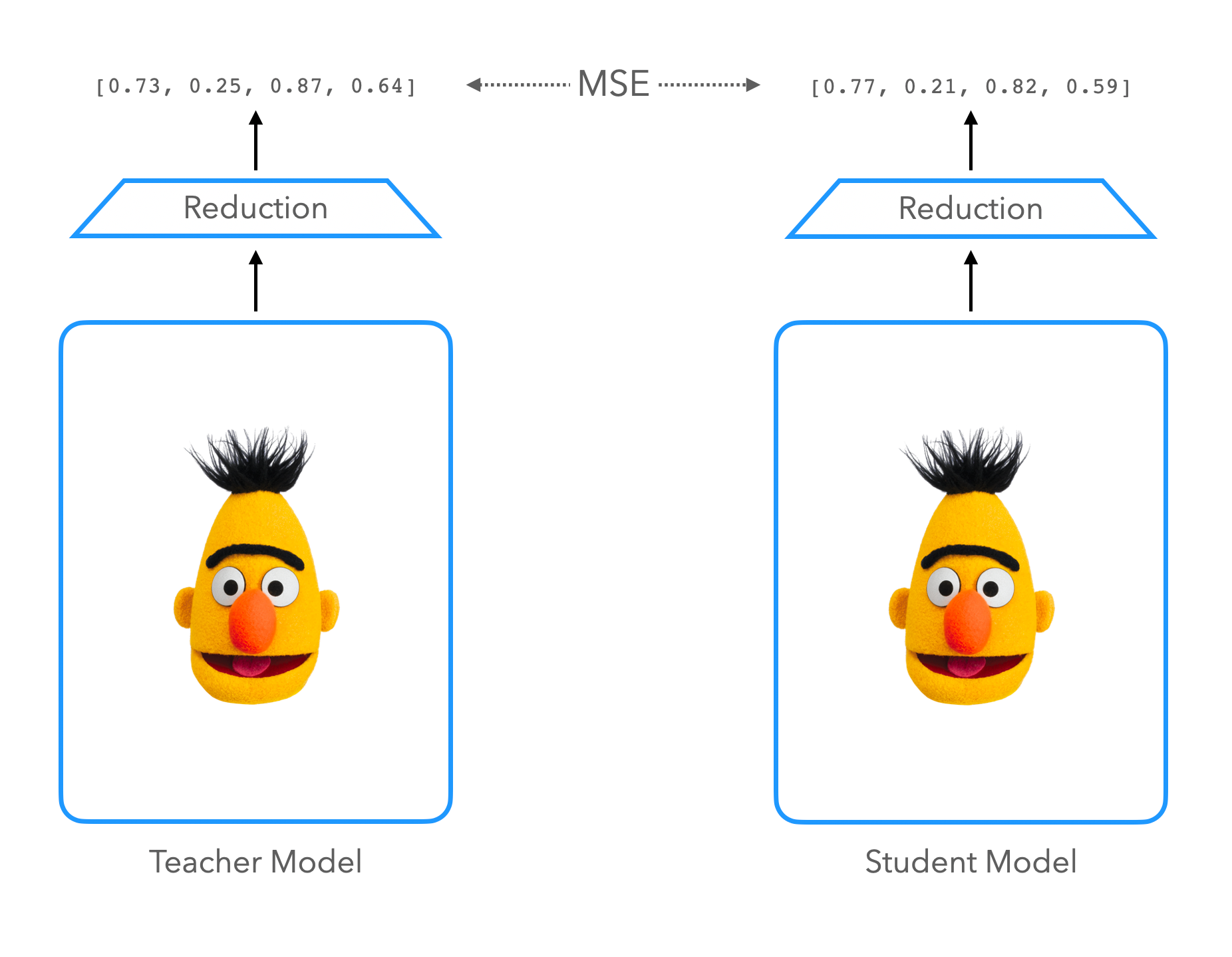
Metric Learning을 수행하는 경우 결국 인코더에서 생성해내는 임베딩의 성능이 전체 모델의 성능을 좌우한다는 점에 착안하여 고안한 방법입니다. $H^S$와 $H^T$가 같은 문장에 대해 각각 Student와 Teacher의 인코더에서 만들어 낸 임베딩이고, $d_{student}$와 $d_{teacher}$의 차원을 갖는다고 할 때, Objective는 아래처럼 정의합니다.
\[\mathcal{L_{emb}} = \begin{cases} \text{MSE}(H^S, H^T) ,& \text{if } d_{student} = d_{teacher}\\ \text{MSE}(H^S W, H^T),& \text{otherwise} \end{cases}\]$W \in \mathbb{R}^{d_{student}\times d_{teacher}}$는 Teacher와 Student의 차원이 다를 경우 정의하는 학습 가능한 파라미터입니다.
Weight Initialization
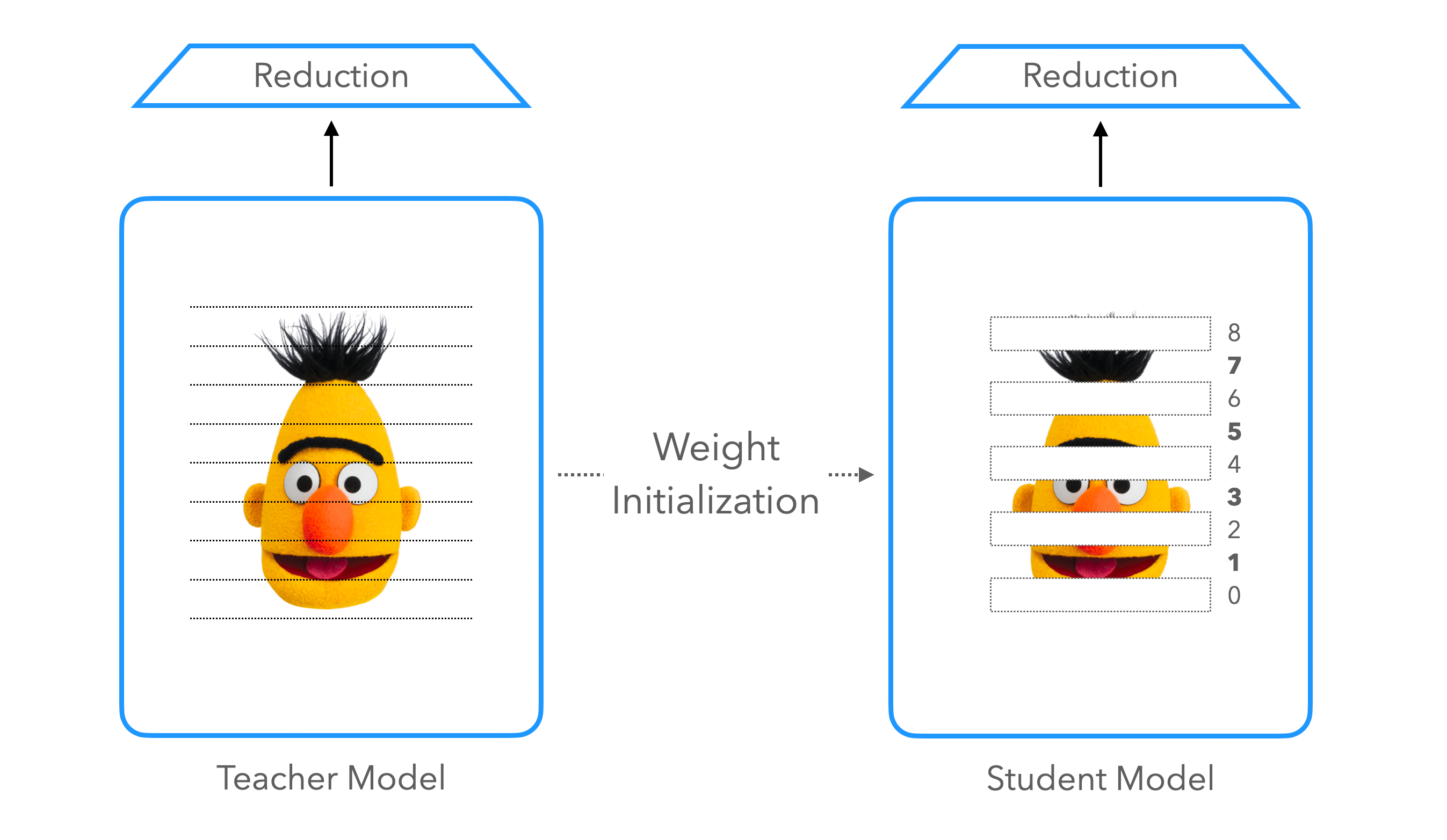
다음과 같은 방식으로 변화를 주어 실험을 진행했습니다. 1) BERT-PKD(Sun et al., 2019)의 방식으로 Teacher의 레이어를 가져와 초기화한 후 Distillation을 진행해보았고 2) Turc et al. (2019)의 방식으로 Student를 사전학습한 후 진행해보았습니다.
첫 번째 방식으로는 트랜스포머 레이어의 크기를 줄일 수 없습니다. 다만 Teacher 모델의 트랜스포머 레이어를 일정 부분 취하여 모델을 구성함으로써 상대적으로 적은 실험을 통해 예측 가능한 속도와 성능을 안정적으로 뽑아낸다는 것이 장점입니다. 예를 들어 8 레이어를 사용하는 Student를 만들기로 결정하였다면 24 레이어의 Teacher에 대비하여 약 3배에 가까운 추론 속도 향상을 불러옵니다.
두 번째 방식은 모바일 환경과 같이 추론 환경의 리소스가 제한되어 있을 때 고려해볼 수 있습니다. 아무리 Teacher 모델의 레이어를 잘라낸다고 하여도 트랜스포머 레이어의 수가 일정량 이상 쌓이지 않으면 성능이 급격하게 떨어지는 만큼, Student 모델의 크기를 더 줄이고 싶을 때 사용합니다. 하지만 Student를 사전학습하지 않으면 사용하지 못하는 방법인 만큼 비용이 많이 드는 방법입니다.
결론
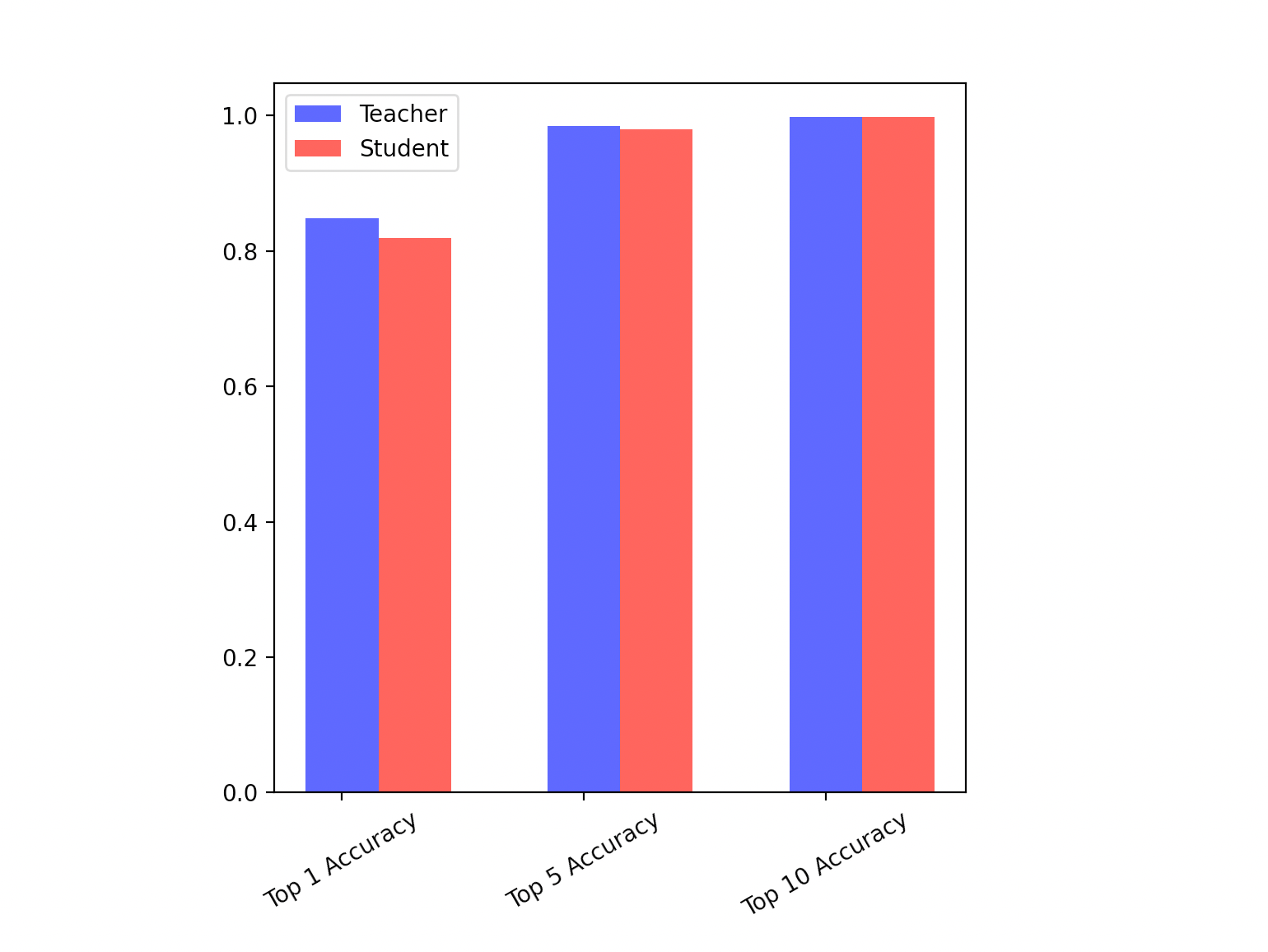
위에서 언급한 것처럼 Teacher는 BERT large를 사용하여 구성하였고, 3개당 하나의 레이어를 취하여 8개의 레이어를 가지는 Student를 만들어 냈습니다. Embedding Distillation을 수행한 후 Prediction Logit Distillation을 수행하고, 추가적인 성능 향상을 위해 Teacher 학습 방식과 동일하게 파인튜닝을 수행하였습니다. 위의 Embedding Distillation, Prediction Logit Distillation, 파인튜닝은 모두 Teacher 학습 데이터의 1/40만 사용하였습니다.
이 경우 3배에 가깝게 속도가 향상되면서, Top 1 정확도는 Teacher 모델의 96.2%, Top 5 정확도는 99.3%, Top 10 정확도는 99.9%를 유지하였습니다.
성능과 속도가 충분히 향상된 모델을 얻었긴 했습니다만, 모델 사이즈와 아키텍처의 측면에서 더욱 공격적인 실험을 하지 못한 점이 아쉬움으로 남습니다. 더 나아간다면 추가로 다음과 같은 것들을 해볼 수 있습니다.
- 더 긴 문맥을 빠른 속도로 연산할 수 있도록 Sparse Transformer 도입
- TensorFlow Serving 환경에서 Quantization 추가
- 트랜스포머 블록 크기 자체를 줄일 수 있는 방법 고안
참고자료
- Distilling the Knowledge in a Neural Network (https://arxiv.org/abs/1503.02531)
- Patient Knowledge Distillation for BERT Model Compression (https://arxiv.org/abs/1908.09355)
- TinyBERT: Distilling BERT for Natural Language Understanding (https://arxiv.org/abs/1909.10351)
- Well-Read Students Learn Better: On the Importance of Pre-training Compact Models (https://arxiv.org/abs/1908.08962)
- DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter (https://arxiv.org/abs/1910.01108)
- Distilling Task-Specific Knowledge from BERT into Simple Neural Networks (https://arxiv.org/abs/1903.12136)
- Generating Long Sequences with Sparse Transformers (https://arxiv.org/abs/1904.10509)